

This is part three of a four part story on utilizing Y-DNA tests to gain knowledge or leads on the patrilineal line of the Griff(is)(es)(ith) family.
The One-Two Punch of Using SNPs and STRs
SNP testing is the new age of genetic ancestry. This is primarily due to the technological advances associated with Y-DNA ‘string ‘ and ‘snip’ testing, the relatively straightforward interpretation of SNPs and dating of STR mutations, the increase of SNP discoveries and the explosive growth of Y-DNA database results.
STR testing and analysis represents the advances of genetic genealogy in the ‘early years’ of genetic gnealology (e.g. 2003 – 2014). However, both continue to provide unique strengths for genetic genealogical research.
During the ‘early years’ of Y-DNA testing, at the turn of the millenium, the popularity of obtaining Y-12, Y-25, and Y-37 STR tests increased. The results were generally reliable but oftentimes their results were mixed when compared with potential corroborating results obtained from traditional paper genealogical sources. A variety of statistical errors were documented such as “convergence” and “back mutation”. Through improvements in statistical analysis, the issues related to the statistical reliability of results were relatively increased and understood.
With Y-111 STR level testing common today, many of the accuracy problems noted in the first decade of the new millenium have been lessened. With more STR markers tested, it is possible to end up with matching or closely matching Y-DNA marker results in individuals who do not share a “recent” common ancestor on the male line. Convergence is more plausible in individuals belonging to common haplogroups. [1]
The use of SNPs are a fairly straightforward process of figuring out where a male lands on a current or possibly new branch of the Y-DNA haplotree. The results of SNP tests are intuitive and easy in analyzing a group of other testers because they uniquely identify the haplogroup branches of descent. You can group testers in branches of a haplotree depending on whether their tests confirm or predict specific SNP mutations that represent specific branches of the haplotree.

In 2020, FamilyTreeDNA added 15,000 new high-coverage Big Y results to the Haplotree analysis, almost 5,000 academic results from present-day men in addition to thousands of ancient DNA results. This resulted in the addition of over 12,500 branches to “The Great Tree of Mankind”. Over 200,000 new unique SNPs were discovered. The growth rate has continued in the past two years. [2]
As indicated in illustration 1, the “One-Two” punch of testing involves using SNPs to provide a general location of Y-DNA testers on the Y-DNA haplotree based on nested haplogroups. Then, ‘the second punch’, if they are available, the use of Y-STR test results can help group test results within recent haplogroup branches and assist in analyzing potential individual matches. The analysis and comparison of individual Y-STR haplotypes can help delineate lineages and tease out branches within the haplotree, fine-tuning relationships between people within the tree.
Illustration 1: Using SNP and STR Results
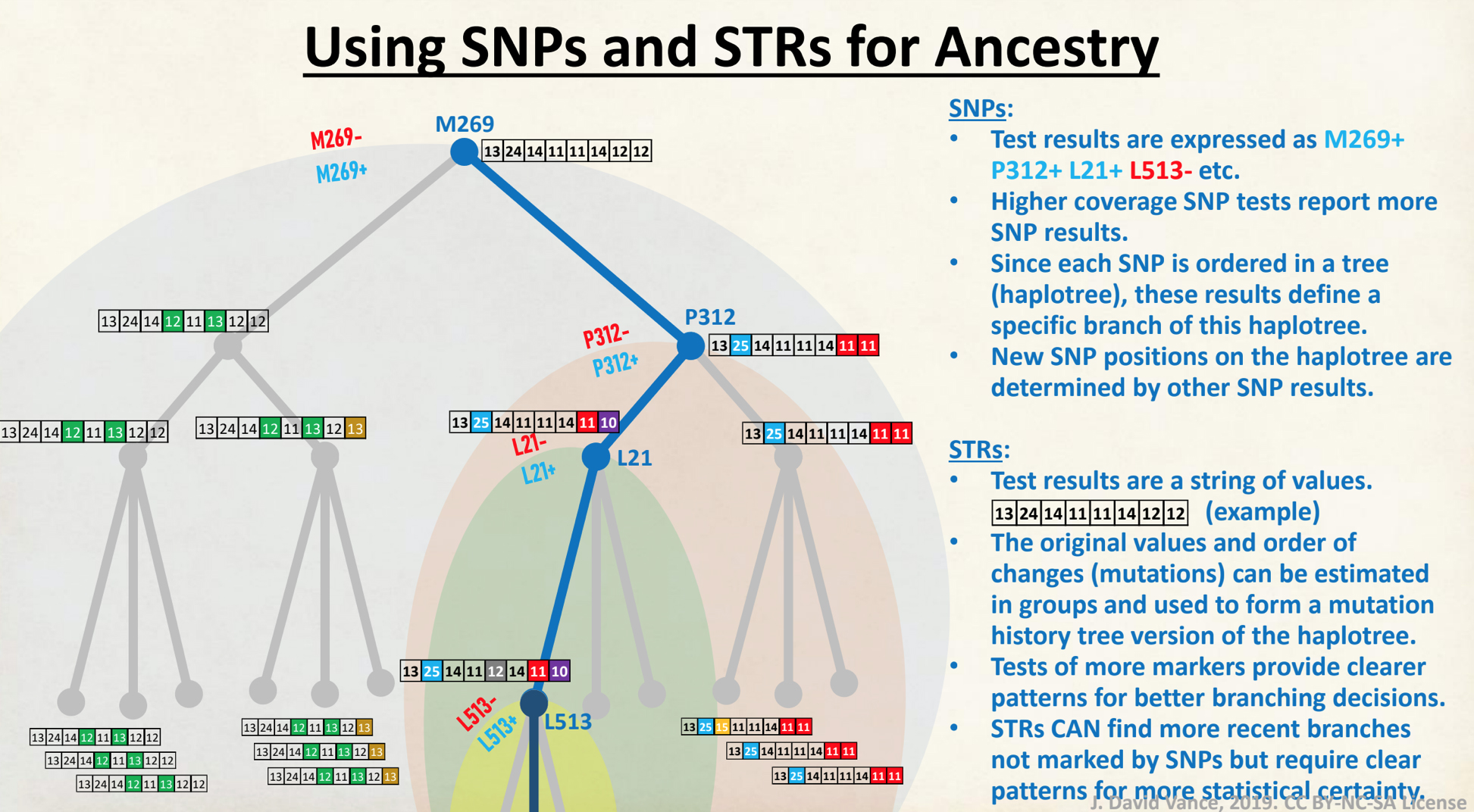
Click for larger view.
The accuracy of haplogroup prediction based on Y-STR haplotypes (as opposed to SNP values) depends mainly on the number of STR values that are tested. Haplogroup predictions based on low-resolution Y-12 to Y-25 STR test haplotypes have a low value of confidence and convergence can be a problem. For many older haplogroups, the Y-STR 25 to Y-STR 37 tests have an acceptable confidence level while for some young haplogroups that emerged with rapid diversification and expansion, the tests do not have enough to discriminate the correct sub-lineage with statistical confidence.
With the growth of next generation sequencing (NGS) tests and whole genome sequencing which report on both STRs and SNPs in a single test, the use of STR-based tests and the need for haplogroup prediction tools is in decline. [3] DNA companies, such as Family Tree DNA (FTDNA) provide NGS tests that predict haplogroup identification as well as identify potential matches with other DNA testers. However, the rub is judging how close are those identified potential matches. The ability to discriminate the accuracy of those matches is still an art form in this mathematically oriented field of genetic ancestry. While FTDNA has developed mathematical strategies to evaluate genetic distance between genetic matches, it is still useful to use other Y-DNA modeling tools to evaluate Y-DNA results.
While STR based haplogroup and genetic prediction tools may be on the decline, they are still helpful in refining and judging potential genetic matches as well as evaluating and discovering the general genetic patterns among the Y-DNA results. SNP data provides information on ancestral male lineage with precision because there are potentially millions of them for comparison and they mutate so slowly that random reversing (“back”) mutations are essentially nonexistent. Neutral SNPs (those not under selection pressure) provide a molecular clock that is good for millions of years that are useful to determine ancient ancestral splits and migrations. STR data, on the other hand, can provide guidance (not necessarily proof) of ancestry in more recent patterns because of their rapid mutation rates. [4]
I have used a number of Y-SNP and Y-STR tools and reports to help with my process of discovery (see Table One). In addition to the FTDNA reports, I have used tools created by individual genealogists that provide creative renditions of the data. For example, assuming there are sufficient testers to compare STR results, mutation history trees and dendrograms can be created illustrate genetic distance and graphically reveal genetic branches from hundreds of years back to the recent past ( fine-tune the smaller branches, ‘twigs’, in a genetic tree). The STR tools are highly effective if used in tandem with SNP data and traditional genealogical information (hence, “the one-two punch”).
Table One : Y-SNP & Y-STR Tools Used in Y-DNA Research
| STR / SNP Tool | Creator | Description |
|---|---|---|
| SNP Tracker | Spencer | Creates a map based on SNP data which traces paternal line from human origins |
| Britain & Ireland SNP & Surname Mapper | Spencer | Based on Surname or SNP input, provides historic British census countywide data and maps |
| Y STR Clustering and Dendrogram Drawing | Spencer | Generate circular/ linear dendrograms from FTDNA data. The tool provides quick and incisive graphic depictions of relationships between test kits on STR values and genetic distance. |
| FTDNA Admin Utilities | Spencer | SNP Breadcrumbs; Find Common Ancestor; Export Tree Text; ISOGG Y-SNP Synonyms; |
| Still Another Phylogeny Program SAPP | Vance | Import Y-STR and Y-SNP data to create phylogenetic tree. This is a great program to use in conjunction with SNP results that group test results in a major SNP branch. The tool can then map out possible lines between testers based on STR values. |
| Y-DNA Matches | FTDNA | Lists Matches based on Y 12, 25, 37, 67, 111, and Big Y 700 STR tests |
| Y-DNA Haplotree | FTDNA | Lists haplotree based on confirmed terminal haplogroup, lists all SNPs tested positive or presumed positive |
| Y-STR Results | FTDNA | Lists the specific test results for Y-111 and Big Y 700 STR tests |
| Big Y BlockTM Tree | FTDNA | A vertical-block visual diagram of Y-DNA haplotree showing Big Y testers. This tool helps you visualize how the paternal lineages are related to each other. Also provides Paternal Countries of Origin and other information. |
| Haplogroup Story | FTDNA | Part of FamilyTreeDNA Discover™ series reports. Based on SNP input, provides estimated time of when haplogroup was born. when did your paternal ancestor live and where are his descendants found today. |
| FTDNATiP™ Report | FTDNA | Provides Genetic Distance estimates for potential Y-DNA STR matches |
While STR tests are used by individual testers to discover possible Y-DNA genetic matches with other testers, the results of STR tests can also provide insights into macroscopic demographic properties that can shed light on lineages and clans – well before the time of surnames. Y- STRs have a time window that runs back to the late Bronze Age.
“STRs … tell us about demography — specifically about bottlenecks and subsequent expansions, namely “founder events.” While SNPs tell us when they were created, STRs tell us about when the population burgeoned after a founding mutation. That SNP and STR clades have a fundamentally different interpretation has caused considerable confusion, but once understood, the methods are very useful complements.” [5]
STRs have been viewed as having limited use in estimating dates beyond about 50-100 generations. However, there have been studies that indicate STR data can be utilized to for genealogical analysis into the Paleolithic era. [6]
Support from Y-DNA Working Group Projects
Coupled with the Y-STR tests, Family Tree DNA offers a wide variety of Y-DNA Group Projects to help further research goals. The group projects are associated with specific branches of the haplotree, geographical areas, surnames, or other unique identifying criteria. Based on their respective area of focus, the research groups have access to and the ability to compare Y-DNA results of fellow project members to determine if they are related. These projects are run by volunteer administrators who specialize in the haplogroup, surname, or geographical region that one may be researching.
FTDNA supports a network of over 11,000 Group Projects to assist and support individuals who are interested in pursuing information about a specific topic related to their genealogy. The projects base research on members’ DNA testing results and to join a project one must test with, manage, or transfer results to FamilyTreeDNA. These working group projects are based on Y-DNA or mtDNA test results and are related to a surname, geographical area of interest, or haplogroup. Illustration 2 provides a graphic example of how a typical Haplogroup project manages Y-SNP and Y-STR test results. [7]
Illustration 2: Structure of a Typical Haplogroup Project
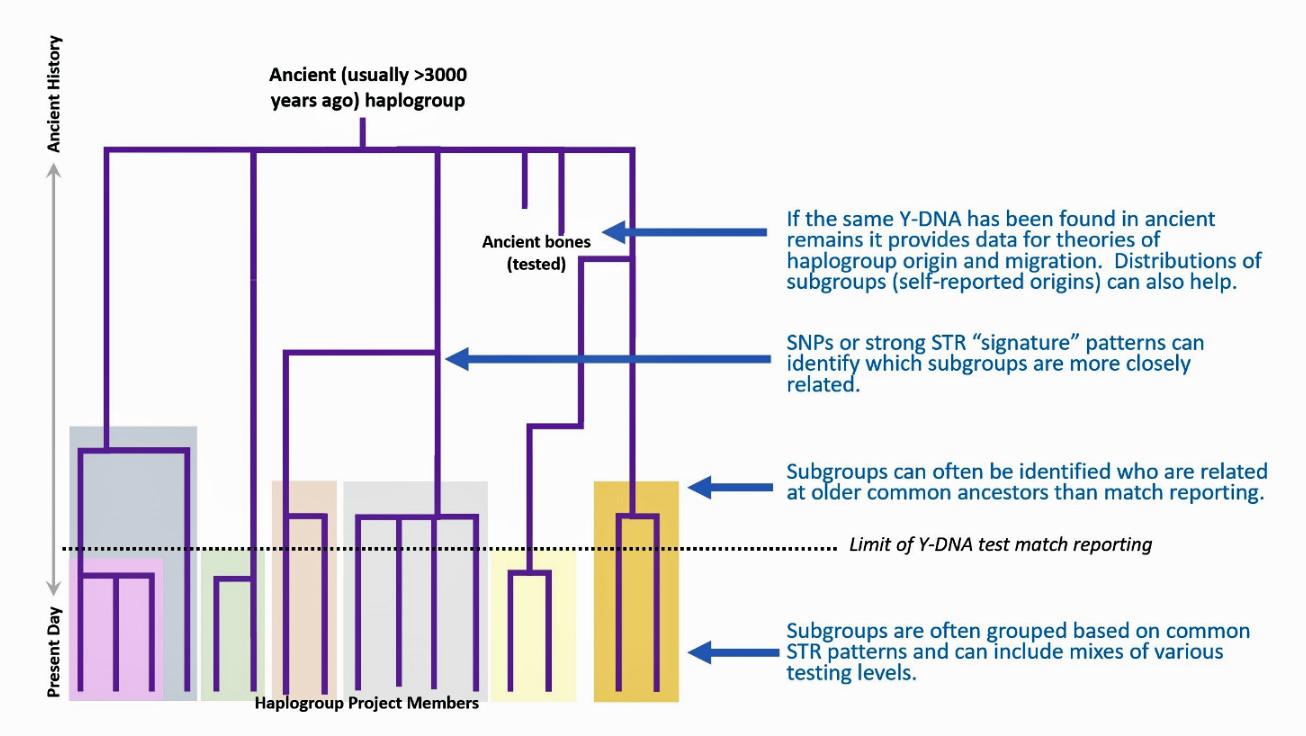
Click for Larger View.
Typically, one of the group project administrators will review your test results (STRs and well as SNPs), known matches and ancestry. The work group administrators will then place your tests in a subgroup within the project. The subgroups are usually based on individuals who have common actual or predicted lower level SNPs. They can then help in calculating the modal haplotype for STRs for the smaller subgroup of testers which can help with the development of a mutation history tree.
For my research on the Griff(is)(es)(ith) family, I joined five Y-DNA Family Tree DNA based projects to assist in my ongoing research:
- The GRIFFI(TH,THS,N,S,NG…etc) surname project is intended to provide an avenue for connecting the many branches of Griffith, Griffiths, Griffin, Griffis, Griffing and other families with derivative surnames. The Welsh patronymic naming system, practiced into the latter 18th century, makes this task more difficult. Evan, Thomas, John, Rees, Owen, Williams and many other common Welsh names may share common male ancestors. (820 members as of the date of this article).
- The G-L497 project includes men with the L497 SNP mutation or reliably predicted to be G-L497+ on the basis of certain STR marker values. The L-497 is a branch or subclade of the G-haplogroup (M201+). The project also welcomes representatives of L497 males who are deceased, unavailable or otherwise unable to join, including females as their representatives and custodians of their Y-DNA. The primary goal of the project is to identify new subgroups of haplogroup G-L497 which will provide better focus to the migration history of our haplogroup G-L497 ancestors. (2,326 members as of the date of this article.)
- The G-Z6748 project is a Y-DNA Haplogroup Project for a specific branch that is a more recent, ‘downstream’ branch from the L-497 branch of the G haplotree. It is a project work group that is a subset of the L497 work group. The G-Z6748 subclade or brand appears to be a largely Welsh haplogroup, though extending into neighboring parts of England. (33 members as of the date of the article)
- The Welsh Patronymics project is designed to establish links between various families of Welsh origin with patronymic style surnames. Because the patronymic system (father’s given name as surname) continued until the 19th century in some parts of Wales, the working group is not limited to a single surname. (1,572 members as of the date of this article.)
- The Wales Cymru DNA project collects the DNA haplotypes of individuals who can trace their Y-DNA and/or mtDNA lines to Wales. Tradition holds that the Celts retreated as far west in Wales as possible to escape invading populations. This project seeks to determine the validity of the theory. This project is open to descendants from all of Wales. (842 members as of the date of this article.)
- The New York State DNA project is a project I recently joined. It is open to all men and women who live in New York State or who can trace their ancestors to New York State. (There are over 3,000 members in this project.)
Two of the six working groups, the G-L497 and the G-Z6748 Haplogroup projects, have been notably helpful in my research with genetic ancestry. The G-L497 working group has a large contingency of test results and a relatively large number of group administrators to help group participants in their research efforts. The administrators of the L-497 working group also provide a wide range of links to reference material associated with the L-497 haplogroup.
The G-Z6748 Haplogroup is a relatively new group and is an offshoot of the L-497 work group. It is a very small group of FTDNA testers that can trace their G- Haplogroup Y-DNA to the British Isles, particularly in the area of Wales.
SNPs, Haplotrees and Haplogroups: Deep Ancestry and Lineages
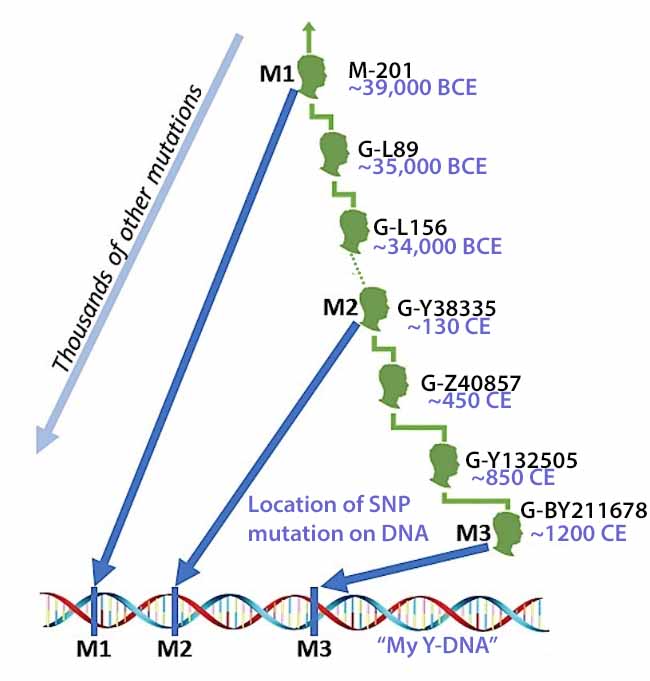
Illustration 3 is an highly simplified example of a branch in a Y-DNA haplotree that shows SNP mutations between generations of descendants. It provides a simple approach for understanding the development of the Y-DNA haplotree with SNP data. [8]
The male at the top of the tree exhibits “mutation one” (M1). This means all of his descendants will exhibit the same mutation. This same nucleotide could change again but the odds are it will not change and it will continue through his lineage. In subsequent generations other male descendants may exhibit single nucleotide changes in other areas of the DNA strand but will continue to exhibit the M1 mutation.
Illustration 3: Example of SNP Mutations and Genealogical Paths
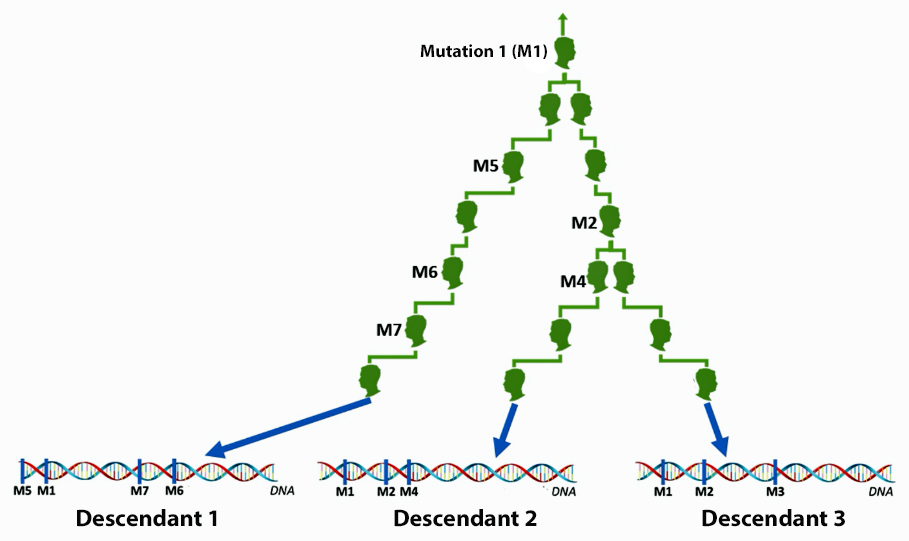
Click for larger view.
In this illustration, we have two branches in the genetic haplotree where on one side a descendant exhibits “mutation 5” and on the other branch a descendant exhibits “mutation 2”. Each of their respective male descendants will respectively exhibit or test positive for M1 / M7 (in the left branch) and M1 / M2 (in the right hand branch) SNP mutations respectively. Descendent 1, at the bottom of the illustration, will test positive for M1, M5. M6. and M7 mutations and negative for M2, and M4 mutations. Descendants 2 and 3 will test positive for M1, M2 and M4 and negative for M5, M6, and M7. Descendant 3 will test positive for M1 and M2 and negative for M4 through M7.
The key to this exercise is one can trace the SNP mutations through successive genetic lines thereby creating a genetic family tree. SNPs are referred to as M1 through M7 in the illustration. Obviously, SNP testing is a bit more complex. SNPs are actually named with a major capital letter(s) and then with a number. [9]
A haplogroup, as previously indicated, is a genetic population group of people who share a common ancestor on the patriline or the matriline. Top-level haplogroups are assigned letters of the alphabet and deeper branches or subclades are labeled depending on what different nomenclature system is used.
The above illustration also greatly simplifies how many SNPs are associated with major branches in the haplotree and does no discuss the number of years between identified branches in the haplotree. Many of the haplotree branches actually represent mutations in various male descendants spanning thousands of years. Also, each branch is typically represented by an accumulation of SNPs that define or are associated with a given branch of the tree.
Illustration 4 below provides a graphic depiction of the relationship between SNPs and haplogroups within the Y-DNA Haplotree. The illustration uses the G haplogroup, as an example. The Griff(is)(es)(ith) paternal line is a part of the G-M201 haplogroup.
Illustration 4: SNPs in Relation to the Haplotree and Haplogroups
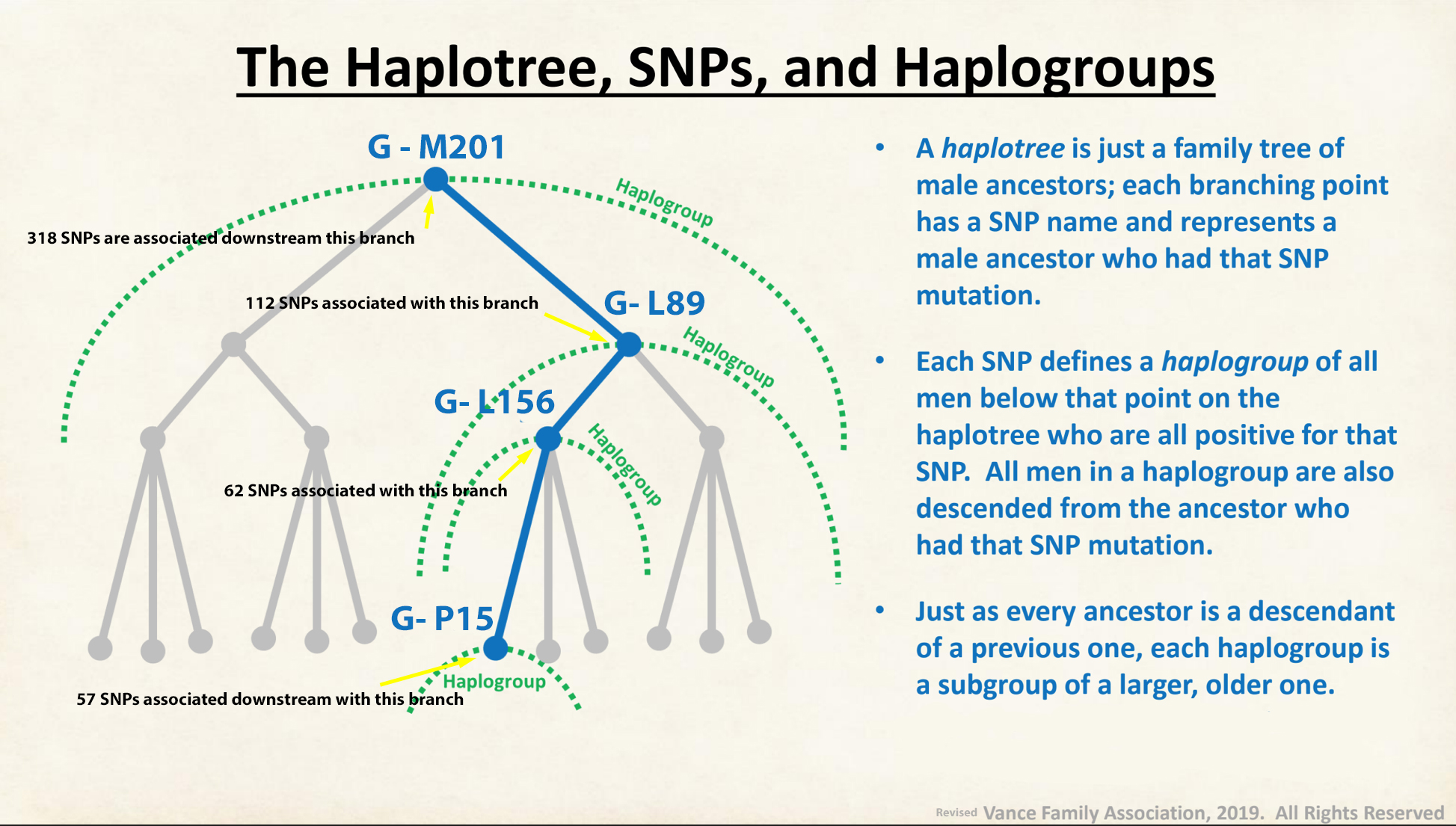
Click for larger view.
Illustration 5 provides a high level view of the structure of the Y-DNA haplotree. The Griff(is)(es)(with) Y-DNA line of descent is part of the Y-DNA G haplogroup that emerged approximately 45,000years ago.
Illustration 5: High Level View of the Y-DNA Haplotree
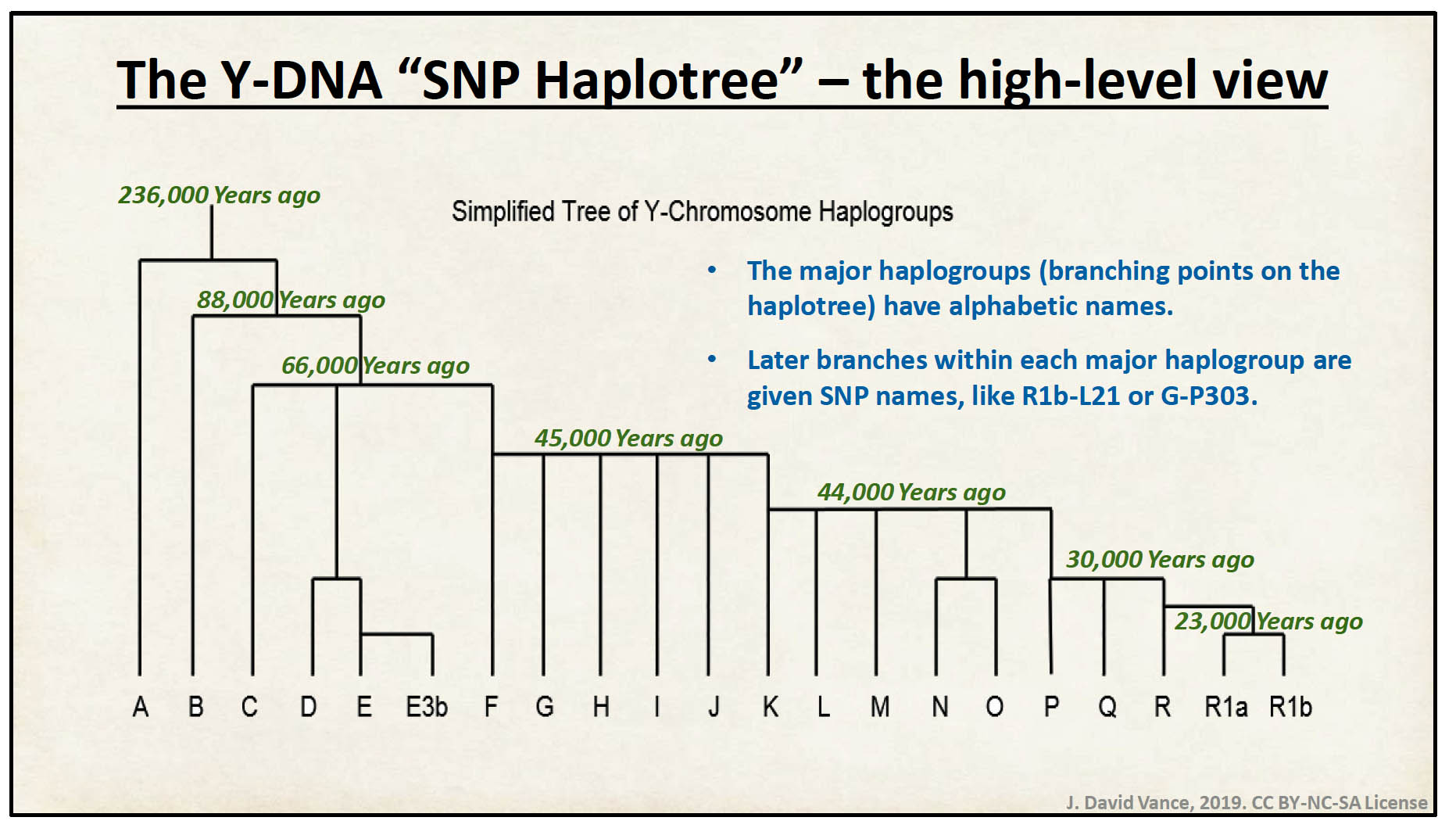
Click for Larger view.
The major Eurasian Y-DNA-haplogroups (E1b, G2a, I1, I2, J1, J2, N, O, R1a, R1b, etc.) formed over tens of thousands of years, typical African Y-haplogroups like A, B and C have even deeper roots.
Haplogroup G descends from haplogroup F, which is thought to represent the second major migration of homo sapiens out of Africa, at least 60,000 years ago. While the earlier migration of haplogroups C and D had followed the coasts of South Asia as far as Oceania and the Far East, haplogroup F penetrated through the Arabian peninsula and settled in the Middle East. Its main branch, macro-haplogroup IJK would become the ancestor of 80 percent of modern Eurasian descendants.
Haplogroup G formed approximately 40-50,000 years ago as a side lineage of haplogroup IJK. Haplogroup G had a slow start in terms of migration, evolving in isolation for tens of thousands of years, possibly in the Near East, cut off from the wave of migration of Eurasia.
Paleolithic lineages (roughly 2.5 million years ago to 10,000 BCE) that underwent serious population bottlenecks, for thousands of years sometimes, have a series of over one hundred defining SNPs in their root branches The root branch (M201) of the G haplogroup of which the Griffis lineage is a descendant has over 300 defining SNPs, confirming that this paternal lineage experienced a bottleneck before splitting into haplogroups G1 and G2 (see footnote 18).
The sub-branch G1 might have originated around modern Iran at the start of the Last Glacial Maximum (LGM), approximately 26,000 years ago. G2 developed around the same time in West Asia. At that time humans in Europe were part of earlier haplogroups and were hunter-gatherers and living in small nomadic or semi-nomadic tribes. Members of haplogroup G2 appear to have been closely linked to the development of early agriculture in the Fertile Crescent, starting 11,500 years before present. The G2a branch expanded to Anatolia (modern day Turkey), the Caucasus and Europe, while G2b diffused from Iran across the Fertile Crescent and east to Pakistan. [10]
Organizational Differences Between Y-DNA Haplotrees
Since 2002, the nomenclature and structure of the Y-DNA haplotree has evolved with various modifications. As indicated in part one of this story, there are four major Y-DNA haplogroup trees managed by various groups. The most widely used versions are managed by (1) the DNA company Family Tree DNA (FTDNA), and two DNA research organizations : (2) YFULL, and (3) the International Society of Genetical Genealology (ISOGG). Each of the companies or organizations have different representations of the tree. They also do not uniformly use the same branches or SNP names. [11]
For Y-DNA, a haplogroup may be shown in the long-form nomenclature established by the Y Chromosome Consortium, or it may be expressed in a short-form version, using a deepest-known SNP. [12] Since 2012 many scholars, companies and genetic genealogists agreed to use what is called a Shorthand – SNP nomenclature Haplotree system to avoid naming confusion for the future. Family Tree DNA also merged to this system. [13] An example of this nomenclaure is found in Illustration 6 for the G haplogroup. The highlighted areas in the illustration trace the Y-DNA line for the Griff(is)(es)(ith) family.
Illustration 6: Example of Basic Hierarchy for Shorthand System Nomenclature for Beginning of the G Haplogroup

The differences between the three primary Y-DNA haplotrees is apparent when comparing my Y-DNA SNP results. Changes in the haplotrees can occur frequently based on incorporating new Y-DNA test results. New test results are not uniformly accepted by each of the three organizations. The differences between the three haplotrees are based on the nomenclature of the specific haplotree, what SNPs are accepted by a particular haplotree, and what SNPs are selected from the same equivalent block of SNPs to identify a particular branch of the Y-DNA haplotree. It makes you cross-eyed trying to follow all of this.

At this point in time, it is noteworthy that my test results put me on the cutting edge of new discoveries in genetic genealogy for the G haplogroup in the British Isles. as new Y-DNA test results are incorporate into the Haplotree, they can have an impact on my position in the Haplotree. Also, not all of FTDNA have been incorporated into the results of the YFULL and ISOGG haplotrees. In the FTDNA haplotree, as reflected in illustration 7 below, my SNP and STR results have been designated as a private SNP haplotree branch, as a subclade off of branch BY211678 along with another subclade branch G-FT119236.
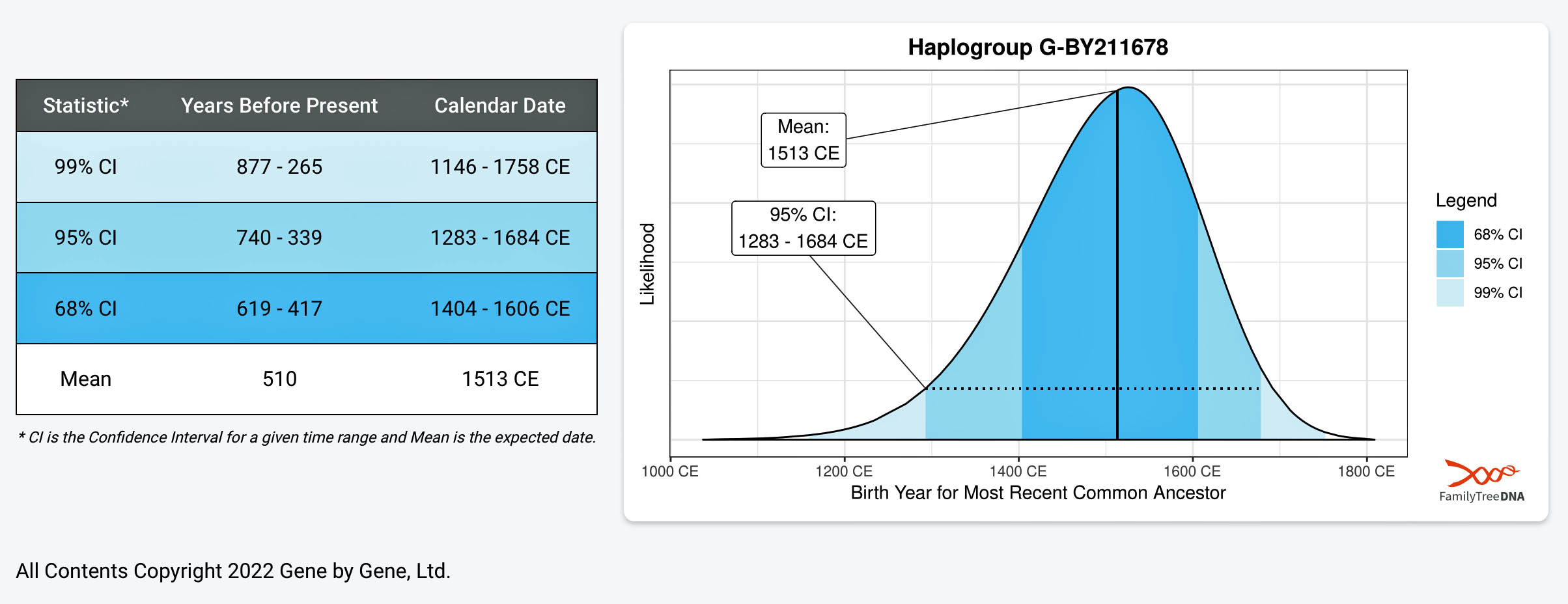
Based on the results of my Big Y-700 FTDNA test, my Terminal SNP (branch or subclade) is G-BY211678. Basically, this means I am the descendant of a male who is the most recent common ancestor (MRCA) of this genetic line who was born ‘around’ 1500 CE with 95 percent statistical confidence variance of being born between 1283 CE and 1684 CE. [14]
Illustration 7 represents the ‘smallest branches and leaves’ of my Haplotree path. The data is from FTDNA’s Block Tree of Big Y test kits. It is a few branches down from the G-P303 branch and the L-497 branch which are most frequent and widespread G sub-haplogroups in Europe. The sub-clades of P-303 have more localized distribution with the U1-defined branch largely restricted to Near/Middle Eastern and the Caucasus and the L497 lineages essentially occur in Europe where they likely originated. [15] The man whose genetic SNP mutations created the G-6748 branch was born around 700 CE.
Illustration 7: Rendition of Portion of FTDNA Big Y Block TreeTM of G- Haplogroup Starting with the G-Z6748 Sub-Branch

Click for larger view.
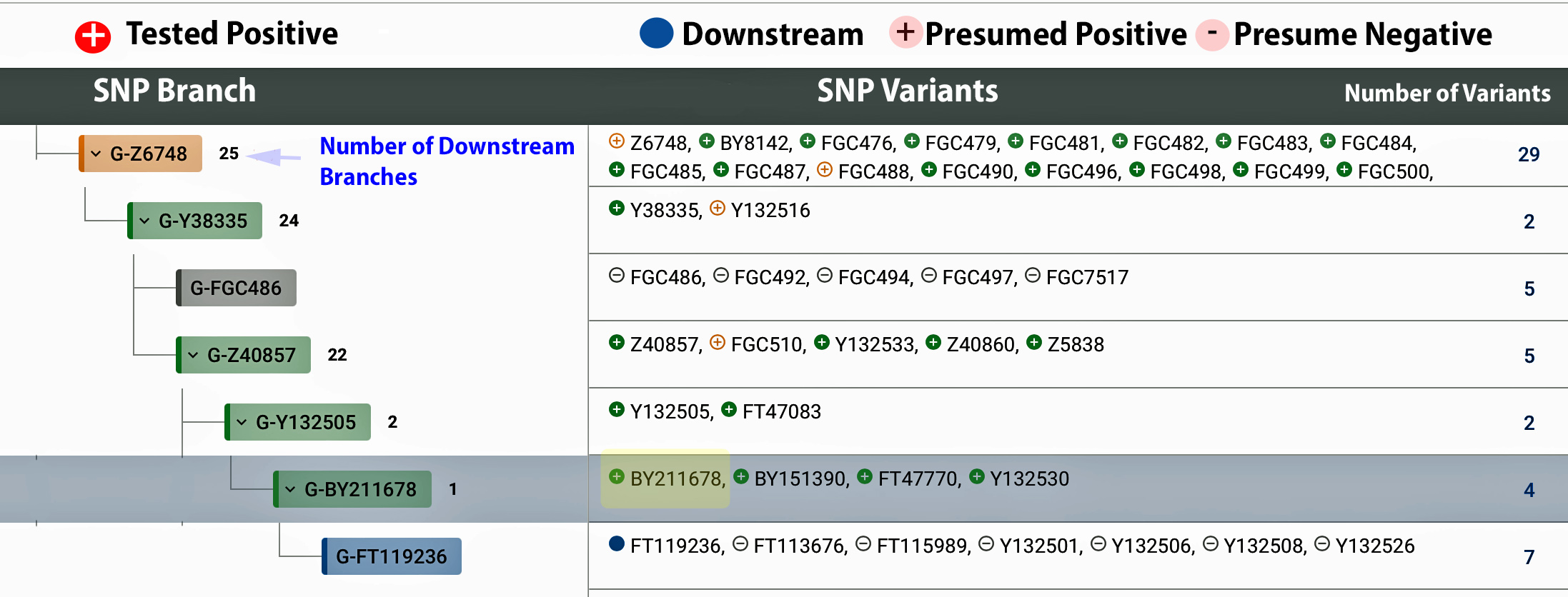
Looking at the haplotree from the view of testing for specific SNPs, as indicated Illustration 8, from G-Z6748, the following branches G-Y38335 > G-FGC486 > G-Z40857 > G-Y132505 trace down to G-BY211678. Since I have tested positive for this SNP, FTDNA has provided a new name for this terminal SNP in 2020: G-BY211678. I am presently the only one that is directly tied to this public SNP. The others have tested for a new downstream branch from this SNP and have formed their own subbranch G-FT119236.
Illustration 8: FTDNA Big Y 700 Y-DNA Test Confirmed Terminal Branch for James Griffis
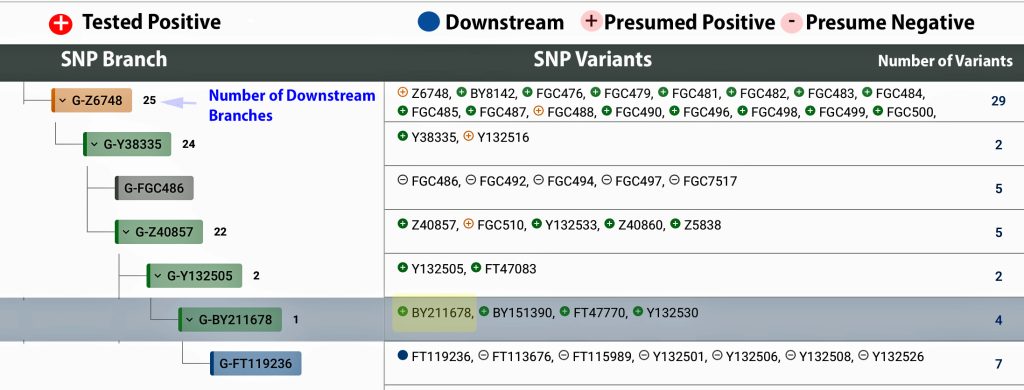
The direct match to the FTDNA newly formed branch BY211678 is not documented in the International Society of Genetic Genealology (ISOGG) or the YFULL haplotrees. Both of these organizations consider my terminal SNP as a private (individual) SNP variant at this moment in time. A new branch is not recognized by ISOGGZ or YFULL until at least two individuals are found to have similar positive test results for the SNPs. However, one step up the haplotree branches, ISOGG has documented G-Y132505 which in long form is G2a2b2a1a1b1a1b1a2b. A designation that one certainly cannot remember! The YFULL haplotree also lists G-BY211678 as a SNP variant under the G-Y132505 branch rather than a subclade branch in the haplotree under G-Y132505. [16]
Given the number of newly discovered SNPs that have formed new branches in the Y-DNA tree, many of these new variant SNPs are yet to be confirmed by ISOGG and YFULL. Most of these new FTDNA SNP variants are considered as private SNPs by the other organizations unil other testers test positive or negative for the SNP. Accordingly, their names will reflect FTDNA names and numbers for the newly identified SNPs.
In the FTDNA haplotree, the ‘Y132505″ branch, is two branches above my terminal SNP position. As of January 2023, my termnial SNP position has been labeled FT48097. The ‘FT’ is an ISOGG based prefix referring to a result from FTDNA Big Y testing. The Y132505 branch is found in the FTDNA, YFULL, and ISOGG haplotrees. The “Y” refers to the source of this SNP’s discovery (YFULL team using published and commercial next generation testing results).
Illustrations 9 and 10 reflect the relative position of my SNP/STR results in the YFULL and ISOGG haplotrees.
Illustration 9: YFULL Haplotree G-Y132505 Branch
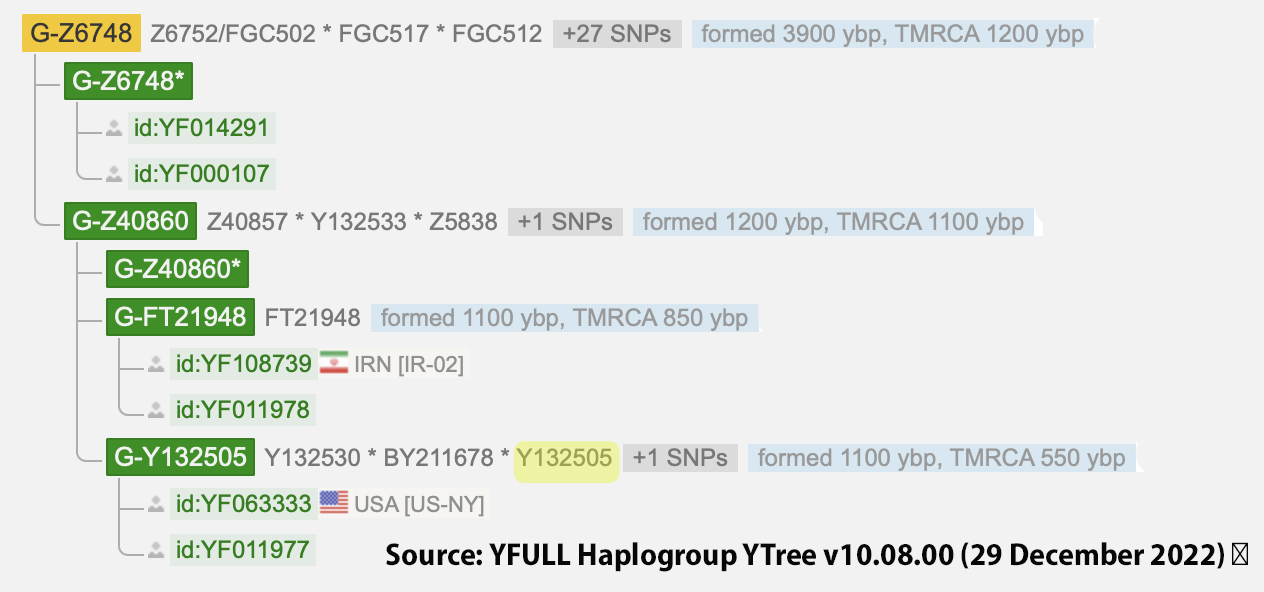
The YFULL haplotree defines the BY211678 SNP as a private individual variant as opposed to a sepate subbranch to G-Y132505.
Illustration 10: ISOGG Haplotree G-Y132505 Branch

The ISOGG haplotree portrays G-Y132505 as the terminal SNP, with no mention of G-BY211678 or G-Y132506.
Equivalent SNPs and Y-DNA Haplotree Branches
Equivalent or variant SNPs are mutations observed in the same block of SNPs for a specific branch or haplogroup. They are equivalent in the sense that they can all be used to describe a haplogroup branch since it is impossible to define the chronological order (time of occurrence) of the SNPs in one haplogroup. [17]
Many haplogroups and subclades in the Y-DNA Haplotree are defined by more than one SNP. All of the Y-DNA public haplotrees are developed from research of ancient human artifacts and by the continuous analysis of test results of men completing Y-DNA tests and developing a SNP mutation history that shows how their ancestors branched from each other. Because many branches have died out long before modern day, any group of tested men will only show a fraction of all branches that actually occurred. Picking a SNP to identify a given branch may not be straightforward if there are more than one available SNP since the chronological order of each SNP may not be known.
Nearly every SNP on every public Y-DNA haplogroup tree is just one label for a block of equivalent SNPS. The equivalent SNPS are different physical mutations so they represent successive mutational genetic generations of men. They are only equivalent as long as the haplotree remains the same and there are no discoveries of descendants associated with a given SNP to differentiate the chronological order. They represent a long series of generations of paternal ancestors who have no other descendants living today who have tested their Y-DNA except for the different groups who descend from different ancestors at the bottom of an equivalent block of SNPS. Any new tester may create a previously unknown branch which descends from a different ancestor inside this long series of generations or block of equivalent SNPs.
“Y-DNA and mtDNA lineages go extinct all of the time. About 80% of all lines have gone extinct through most of recorded history; this is how surnames vanish… . A ‘founder’ event occurs when a line almost goes extinct but then recovers, which leaves a clear imprint on descendants’ DNA.” – Rob Spencer
Surnames and Y lineages go extinct far more often than most people realize. However, everyone probably has family experiences of having sisters, bothers, aunts or uncles with no children, or relatives with daughters but no sons — which is exactly how Y-DNA line extinction happens.
Until the mid-1800’s (with the notable exception of colonial North America), any given Y lineage had a 70-75% likelihood of going extinct within about 5 generations. [17a]
This has a strong impact on Y DNA genealogy. For the rarer haplogroups which includes the Griff(is)(es)(ith) genetic line (e.g. Haplogroups E, G, T, J are the rarer lineages in Europe), it is not unusual to find that one’s Y SNP lineage ‘ jumps’ from the Bronze Age to the present without any haplogroup branching. Males were no doubt born all along the way but with low numbers and with few branches, many died out before anyone would survive to take a DNA test. Illustration X provides a graphic depiction of the probability of Y-DNA extinction base on general historical time periods. [17b]
Illustration 10a : Probability of Y-DNA Lines of Extinction by Time Period
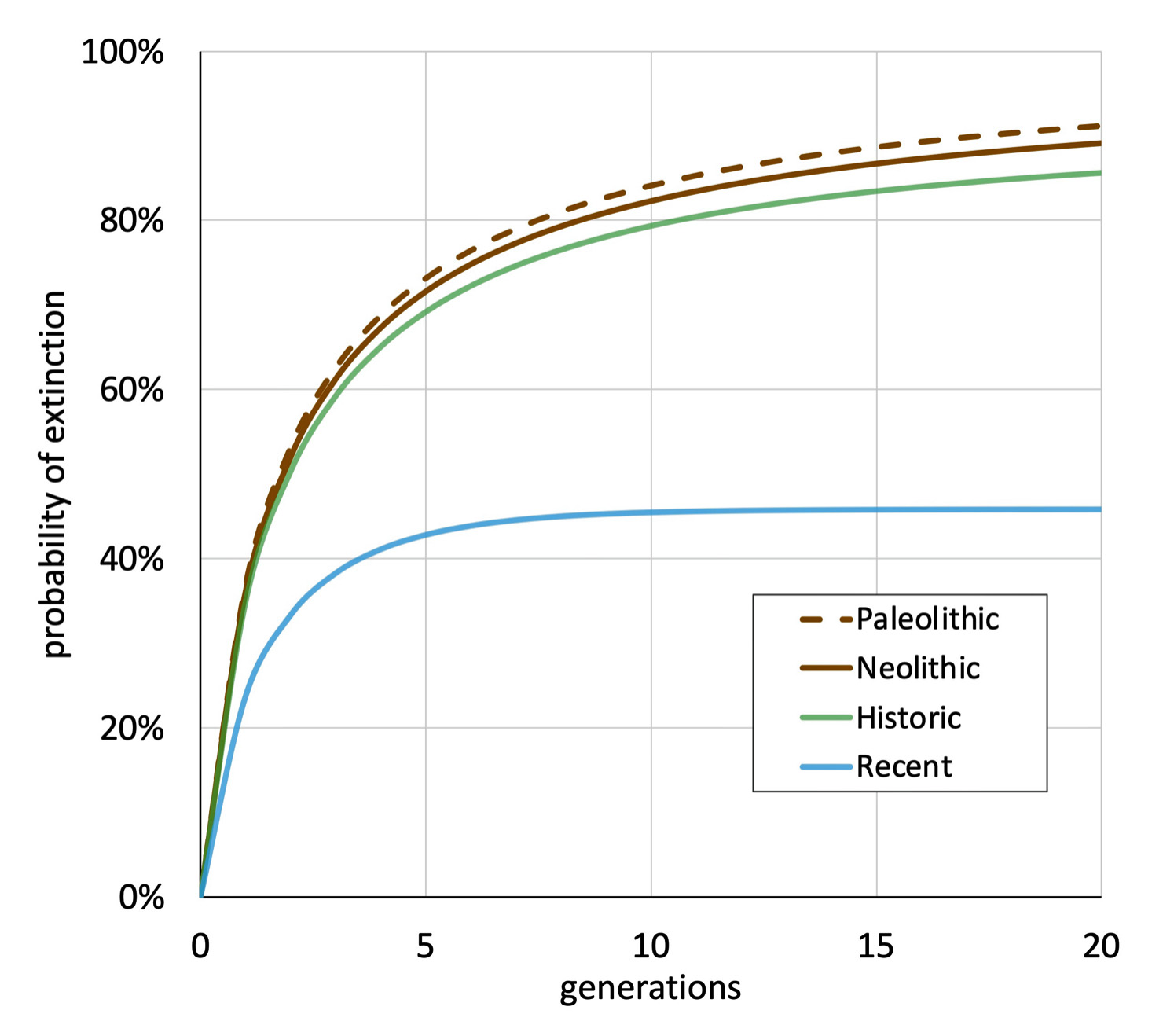
Generally speaking the number of accumulated SNPs between a haplogroup and its direct subclade correlates roughly to the number of genetic generations elapsed between the two branches. It is highly unlikely that only one genetic generation (e.g. 33 years) can be used as a multiplying factor for gaging time between two branched based on the number of equivalent SNPs associated with the older branch.
Illustration 10 provides an example of some of the major branches or subclades (SNP mutations ) of the G haplogroup of which the Y-DNA of Griff(is)(es)(ith) family can be traced. The illustration also indicates the number of variant or equivalent SNPS associated with a particular branch. For a list of all the equivalent SNPs in the Griff(is)(es)(ith) line, see footnote [18]. Illustration 10 also indicates the approximate date of when the branch occurred (e.g. when a male exhibited a specific SNP mutation).
Illustration 10: SNP mutations and the Patrilineal Line for Griffis Family
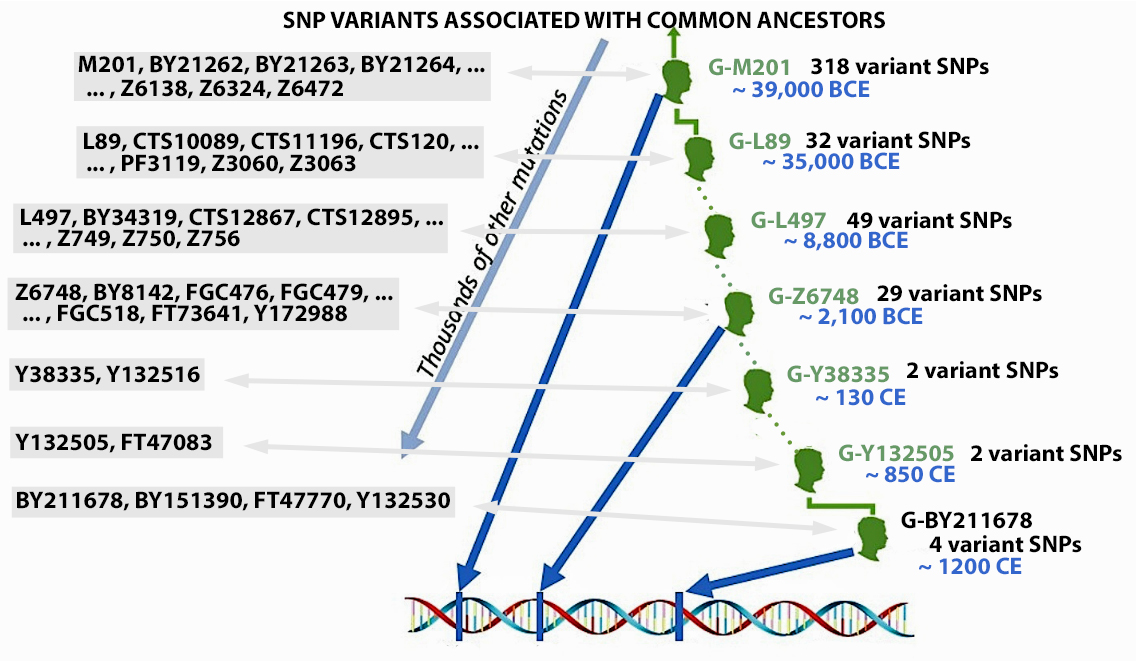
The Griff(is)(es)(ith) Patrilineal Y-DNA Line: The Big Picture
Based on the results of my Big Y 700 SNP test from FamilyTree DNA, Table Two provides a general outline of the major SNPs that represent major mutations in my Y-DNA line of genetic ancestors. Each of these SNPs represent a common ancestor that had a Unique Event Polymporhism (UEP) which represents the beginning of a new Y-DNA branch in the haplotree. The table traces major mutations from the beginning of of the G Haplogroup all the way to my most recent common Y-DNA ancestor G-BY211678 through the G Haplogroup.
Table Two: Griff(is)(es)(ith) Y-DNA Lineage on the Family Tree DNA (FTDNA) Haplotree
| FTDNA Y Branch Subclade Main SNPs | Age Estimate | Time Passed (Years) From Preceding Branch | Phylo- genetic Sub- clades | SNP Branch Variants / Equiv- alent SNPS | Down Stream Branches ~ 2022 | Number of Descendants in FTDNA Database 01-14-22 |
|---|---|---|---|---|---|---|
| GHIJK- F1329 | 46,000 BCE | < 1,000 | 2 | 214,467 | ||
| G-M201 | 26,000 BCE | 20,000 | 2 | 318 | 1,731 | 9,658 |
| G-L89 | 24,000 BCE | 20,000 | 2 | 112 | 1,623 | 6,133 |
| G-L156 | 20000 BCE | 4,000 | 2 | 62 | 1,621 | 6,103 |
| G-P15 | 16000 BCE | 4,000 | 2 | 57 | 1,541 | 5,748 |
| G-L1259 | 16000 BCE | < 1,000 | 2 | 7 | 1,403 | 5,007 |
| G-L30 | 13000 BCE | 3,000 | 2 | 47 | 1,226 | 4,519 |
| G-L141 | 12000 BCE | 1,000 | 2 | 14 | 1,018 | 3,806 |
| G-P303 | 9700 BCE | 2,300 | 3 | 38 | 959 | 3,629 |
| G-L140 | 9000 BCE | 700 | 3 | 14 | 907 | 3,298 |
| G-PF3346 | 8950 BCE | < 100 | 2 | 1 | 896 | 3,167 |
| G-PF3345 | 8900 BCE | < 100 | 11 | 3 | 889 | 3,145 |
| G-L497 | 5300 BCE | 3,600 | 2 | 49 | 456 | 1,747 |
| G-CTS9737 | 4400 BCE | 900 | 2 | 12 | 449 | 1,632 |
| G-Z1817 | 3000 BCE | 3,000 | 2 | 15 | 436 | 1,575 |
| G-Z727 | 2450 BCE | 550 | 3 | 8 | 431 | 1,464 |
| G-FGC477 | 2100 BCE | 300 | 5 | 2 | 52 | 113 |
| G-Z6748 | 700 CE | 2,800 | 2 | 29 | 22 | 49 |
| G-Y38335 | 750 CE | < 100 | 2 | 21 | 2 | 43 |
| G-Z40857 | 1000 CE | 250 | 3 | 5 | 19 | 41 |
| G-Y132505 | 1250 CE | 250 | 3 | 2 | 2 | 7 |
| G-BY211678 | 1500 CE | 250 | 2 | 4 | 1 | 5 |
The following provides an explanation of the information found in Table Two.
Column One: Name of ancestral haplogroup in the FTDNA Y-DNA haplotree.
Column Two: Age estimate is the estimated time when the most recent common ancestor of this lineage was born. The date is an estimate based on genetic data. The date is within a 95 % statistical confidence level that the most recent component ancestor of all members to each of these specific haplogroups was born at the stated time. The figure is the most likely estimate in that 95% statistical band and rounded to the nearest 100 or 50.
Column Three: Time passed is the elapsed time between a given haplogroup and its ancestral haplogroup. A large number can suggest a small population size or a bottleneck, causing only one lineage to survive for a long time.
Column Four: Phylogenetic subclades refers to the number of immediate descendants with UEP SNP mutations. A large number indicates a rapid expansion event.
Column Five: SNP branch variants refers to the number of Equivalent or variant SNPs mutations observed in the same block of SNPs for a specific branch or haplogroup. They are equivalent in the sense that they can all be used to describe a haplogroup
Column Six: Number of Downstream branches refers to the number of subclades below this paerticular branch in the tree.
Column Seven: Number of tested modern descendants is the number of present day DNA testers confirmed to belong to this haplogroup.
One can get a sense of the general characteristics of genetic change at the macroscopic level in a given haplogroup line of descent by reviewing specific aspects of when major SNP mutations occurred and the elapsed time between a given haplogroup and its ancestral haplogroup. In general, the Y-DNA line for the Griff(is)(es)(ith) paternal line suggests an historical line of descent that encountered a high rate of male line extinction. Look at the numbers in column 4. The number of new genetic branches are relatively small. Look at the numbers in column 3. The number of years between branches are large. I have identified the figures in bold in column 3.
The G haplogroup and my specific genetic line of descent survived a succession of ‘genetic hardships’ for survival. With the exception of two points in time, the average number of new phylogenetic subclades or the number of immediate descendants with UEP SNP mutations typically reflected only 2 new branches. Despite having a number of equivalent SNPs at each of the major branches, there were not many genetic branches that survived. Around 8,900 BCE the subclade BCE G-PF3345 had 11 branches and around 2,100 BCE the branch G-FGC477 had 5 subclades, suggesting some genetic proliferation at this time period.
Because many branches have died out long before modern day, many of the branches of the haplotree will only show a fraction of all the branches that actually occurred. The extinction of Y-DNA lines is the result of a number of cultural (war, patrilineal competition), environmental (famine, disease, climate), and biological factors (no male offspring) and is one facet of the overall growth, contraction and expansion of human population.
“Three major movements of people, it now seems clear, shaped the course of European prehistory. Immigrants brought art and music, farming and cities, domesticated horses and the wheel. They introduced the Indo-European languages spoken across much of the continent today. They may have even brought the plague. The last major contributors to western and central Europe’s genetic makeup—the last of the first Europeans, so to speak—arrived from the Russian steppe as Stonehenge was being built, nearly 5,000 years ago. ” [19]
While each of these 3 waves of migration were composed of a mix of genetic haplotypes, each were represented by one or two major genetic haplogroups.
Illustration Eleven: The Three Waves of Human Migration to Europe
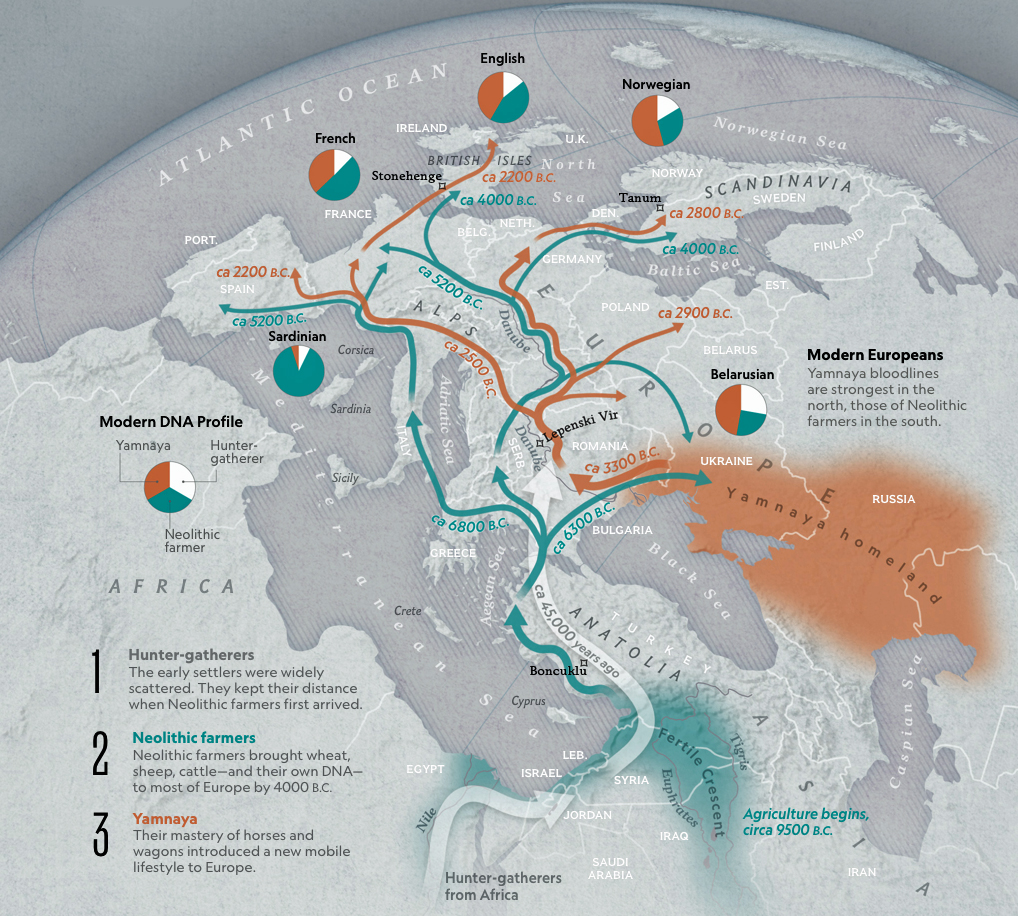
Illustration 12: DNA Legacy of Europe

About 45,000 years ago, the first modern humans ventured into Europe. The first wave of modern Europeans lived as hunters and gatherers in small, nomadic bands. They followed the rivers into western and central Europe. 45,000 years ago. Their DNA indicates they mixed with the Neanderthals. As Europe was gripped by the Ice Age, the modern humans inhabited the ice-free areas of Southern Europe. About 14,500 years ago, as Europe began to warm, humans followed the retreating glaciers into Northern Europe.
The second wave is associated with the migration of Neolithic farmers from the Anatola region. The G-Haplogroup was part of this second wave. They brought not only their DNA but sheep, cattle and wheat to Europe. Within a thousand years the “Neolithic revolution” spread north through Anatolia and into southeastern Europe. By about 6,000 years ago, there were farmers and herders all across Europe.
The third wave, which is predominantly represented by the Yamnaya and are part of the R-Haplogroup, emanated from the Steppes. By 2800 B.C, archaeological excavations show the Yamnaya had begun moving west out of the Steppes. As they proceeded westward, things stated to change. All across Europe, thriving Neolithic settlements shrank or disappeared altogether. The dramatic decline has puzzled scientists from various fields of study and there are various hypotheses that attempt to explain this genetic decline and replacement by the R-haplogroup.
Within a few centuries, the presence of Yamnaya DNA had spread as far as the British Isles. In Britain, similar to other European areas, hardly any of the farmers who lived in Europe survived the onslaught from the east. Until then, farmers had been thriving in Europe for millennia. The second wave of human had settled from Bulgaria all the way to Ireland, often in complex villages that housed hundreds or even thousands of people.
One of many possible theories of the dramatic decline of G-Haplogroup along with other genetic haplogroups associated with the Neolithic farmers is the discovery that some of DNA samples of the Yamnaya contained an early form of Yersinia pestis—the plague microbe that killed roughly half of all Europeans in the 14th century. [20] Unlike that flea-borne Black Death, this early variant had to be passed from person to person. The steppe nomads apparently had lived with the disease for centuries, perhaps building up immunity or resistance. Similar to the history of smallpox and other diseases that ravaged Native American populations, the plague, once introduced by the first Yamnaya, might have spread rapidly through crowded Neolithic villages. That provides a plausible explanation of collapse and the rapid spread of Yamnaya DNA.
While it is a cogent explanation, this theory begs the question of whether there is evidence to substantiate the presence of plague DNA in ecological finds. It has only recently been documented in ancient Neolithic skeletons, and so far, no one has found anything like the plague pits full of diseased skeletons left behind after the Black Death. If a plague wiped out most of Europe’s Neolithic farmers and the G-Haplogroup, it left little trace.
There is strong evidence of major founder events at the end of the Neolithic period. It has been stated that two-thirds of all European men from the R-haplogroup descend from just three ancestors who lived in the late Neolithic. [21] The G-Haplogroup migrated into Western Europe prior to the R-Haplogroup but had similar genetic / demographic impacts at two different time periods, as mentioned above.
Changes in genetic variation are driven not only by genetic processes, but can also be causes or be correlated with cultural or social changes. An abrupt population bottleneck specific to human males has been inferred across several Old World (Africa, Europe, Asia) populations between 5000–7000 BP (5,000 BCE – 3000 BCE). [22]
Combining anthropological theory, population genomic studies and mathematical models, a number of studies have proposed a general sociocultural hypothesis involving the formation of patrilineal kin groups and intergroup competition among these groups as having led to a reduction of Y chromosomal diversity. This reduction was much greater than the reduction in male population size, while keeping the female population size stable.. Various analyses of DNA data show that this sociocultural hypothesis can explain the inference of the population bottleneck in this time period. [23]
Using Rob Spencer’s SNP Tracker to provide illustrative examples of the migratory paths of various haplogroups [24], I compared (Illustration 13) the migratory path of my haplogroup (part of the second wave) with the migratory path of one of the major R-haplogroups, the R1b-M269 haplogroup (part of the third wave). Why compare my haplogroup with this uniquely named haplogroup? The R1b-M269 is a branch of the R-haplogroup that has been associated with the Beaker Culture that was prominent in Western Europe and eventually migrated to Scotland.
Illustration 13: Estimated Migratory Paths for R1b-M269 Haplogroup and the G-BY211678 Haplogroup
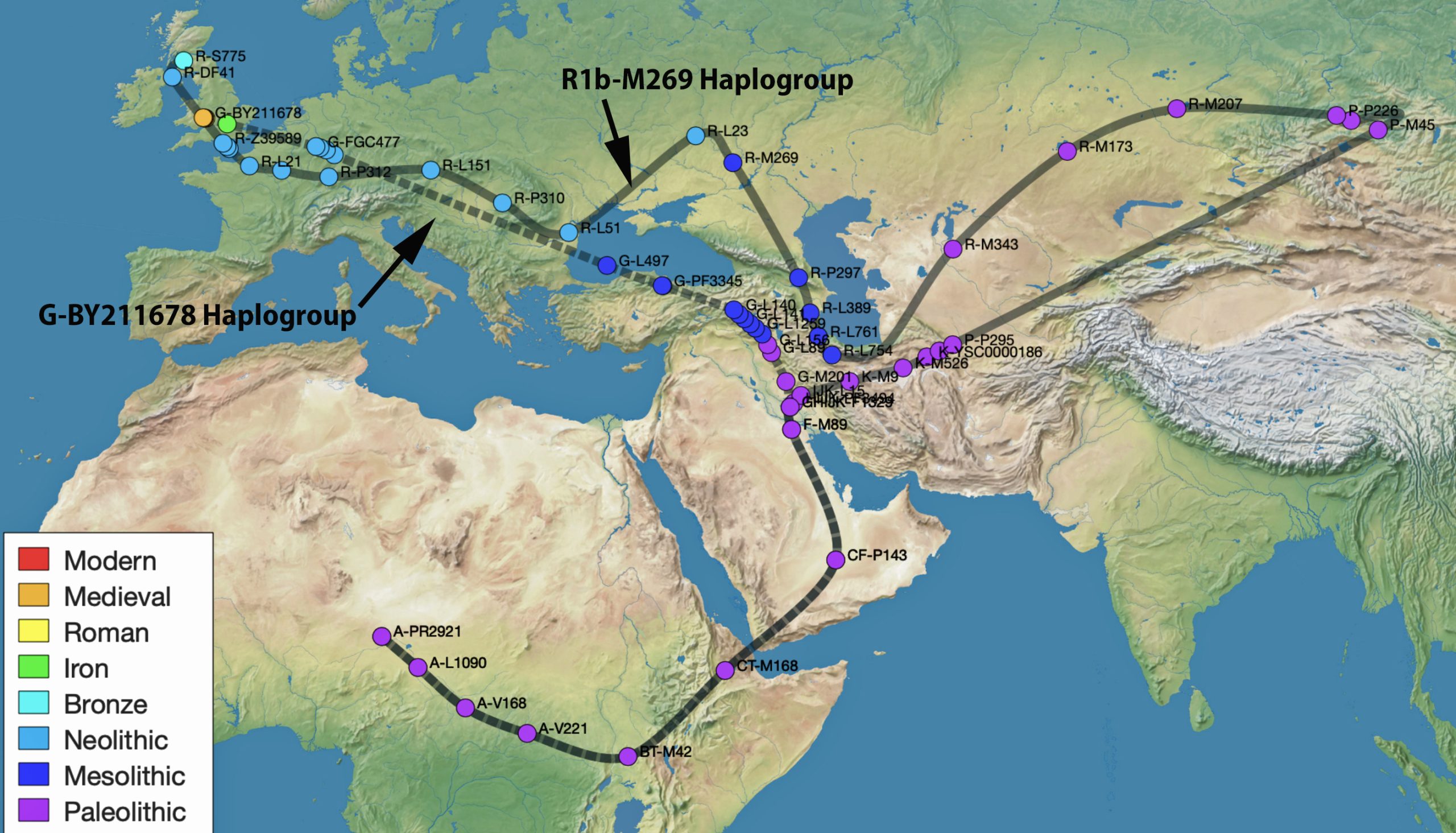
As you can see in the illustration, there is some geographical overlap with the two migratory paths in Western Europe of these two haplogroups. My hunch, (“I did stay at the Holiday Express“) is that my Haplogroup descendants were part of the second wave migration into Europe and eventually were in areas now considered as Germany between 5000 BCEto 2350 BCE and then migrated further westward to what is now northern France and the migrated to the British isle.
As discussed in Part Two of the story, cultural and genetic genealogy are two logically distinct aspects of genealogy. Similarly, various migratory patterns associated with Haplogroups do not necessarily imply that they coincide with cultural geographical patterns or movements. Migratory patterns of Y-DNA Haplogroups undoubtably contained a mix of haplogroups. Y-DNA haplogroups also were represented in various historical cultures. Many cultures invariably contained genetic mixtures of Haplogroups at various periods of time.
Illustration 14 provides a map that ties Y-DNA haplogroups with early Bronze age cultures that were present in Europe. [25] This approximates the time period where I believe the Griff(is)(es)(ith) G-Haplogroup line may have intersected with the R-Haplogroup and were both part of the Beaker and Corded Ware Cultures.
Illustration 14: Associations of Early Bronze Age Cultures with Y-DNA Haplogroups
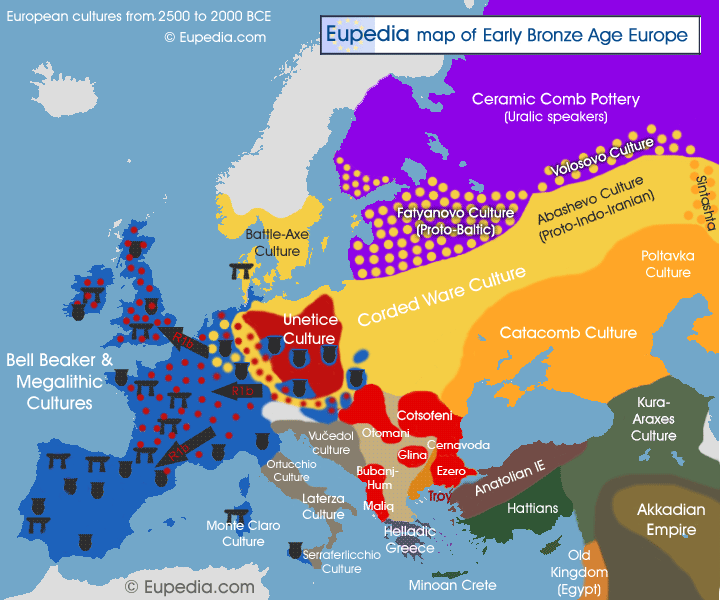
{kind=link}
{kind=link}

The Griff(is)(es)(ith) patrilineal descendants may have encountered the third wave’ of European migrants in the northwest Europe perhaps around 2,500 BCE . They survived a possible plague as well as any possible socio-cultural kinship battles and assimilated into the evolving culture of the times and remained in Northern/Western European area until around or before the Norman invasion (1100 CE). At that time it would appear our descendants migrated to the British Isles, utlimately to Wales.
Using STR Results to Clarify Lineages Before the Advent of Surnames
As stated, the analysis of SNP and STR test results provide a one-two punch in mapping Y-DNA lines of descent. As reflected in the above discussion, the use of SNP data is relatively straightforward. Your placement on the Y-DNA haplotree is based on which SNPs test positive in your Y-DNA tests.
There are a number of Y-DNA tools that can be used to analyze Y-DNA STR results. [26] A mutation history tree portrays the likely haplotype of a most recent common ancestor and the most likely series of STR mutations which occurred in the descendant branches to arrive at the haplotypes of the present day testers (ancestral haplotype).
Comparing STR test results require “more mathematical work” to be useful, and are highly dependent on the number STRs tested. Since STRs mutate at variable rates more frequently than SNPs, one must eliminate the effects of convergence and the mathematically incorporate the differential effects of mutation rates on STR markers.
” . . . (A)ll STR data — Y12 to Y111 — are very reliable for exclusion: you can say with very high confidence that two people are not related if there is a strong mismatch of their STR patterns. This is the forensic use of DNA: it’s very powerful in proving innocence while less decisive about proving guilt.” [27]
FTDNA provides a number of Y-DNA tools and organizational strategies for analyzing Y-DNA results that facilitate “the two-punch process”. SNP results are first used to figure out where one is situated in the Y-DNA haplotree. Depending on the type of Y-DNA tests that are completed, a tester can determine their relative position on the Y-DNA haplotree. The more detailed the test, the more accurate and reliable are the results of placement on the haplotree. The Y12 through Y67 tests will give you a general idea of your haplogroup while the Y111 test will place in one of the more defined branches of the tree. The Big Y700 test will identify the specific ‘twig’ or leaf’ of the tree. STRs can then be used to compare testers that are grouped by haplogroup to discover possible genetic matches or fine tune the branches of the haplotree.
This is where things can get interesting in terms of potential genetic matches and teasing out one’s genetic lineages before the use of surnames.
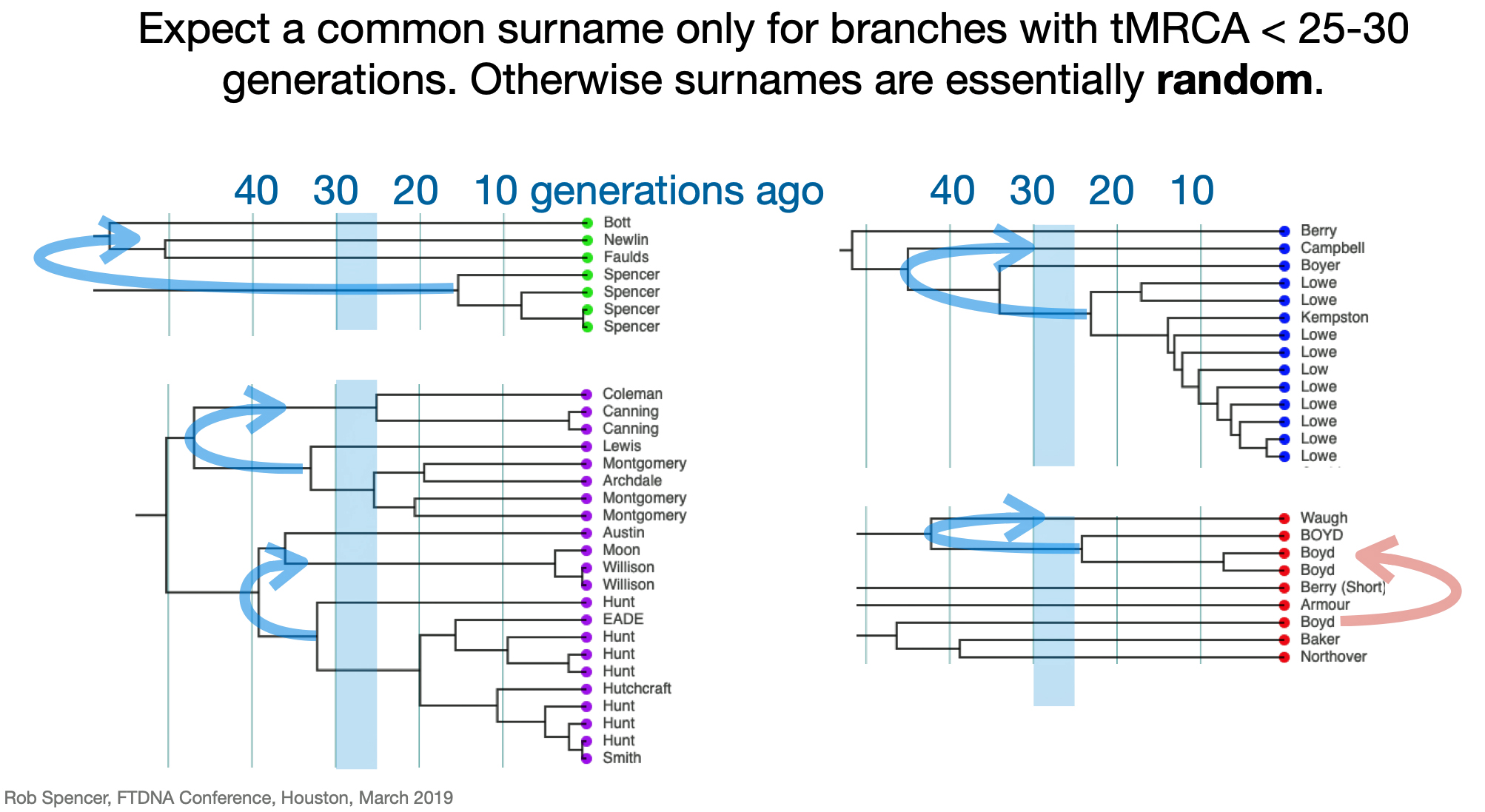
For genealogy within the most recent fifteen to twenty generations (about 500 to 660 years ago), STR markers help define paternal lineages and patterns around the advent of the use of surnames. For Welsh descendants the number of generations will be closer in terms of when surnames were routinely used. STR analysis is an excellent approach to document genetic lineages before the use of surnames and into a period in which surname of genetically matched test kits could be different. For patrilineal lines a descent with Welsh surnames, this is important. The likelihood of finding genetic matches with test kits associated with different surnames is highly likely! [28]
Illustration 13: Genetic Matches and Surnames
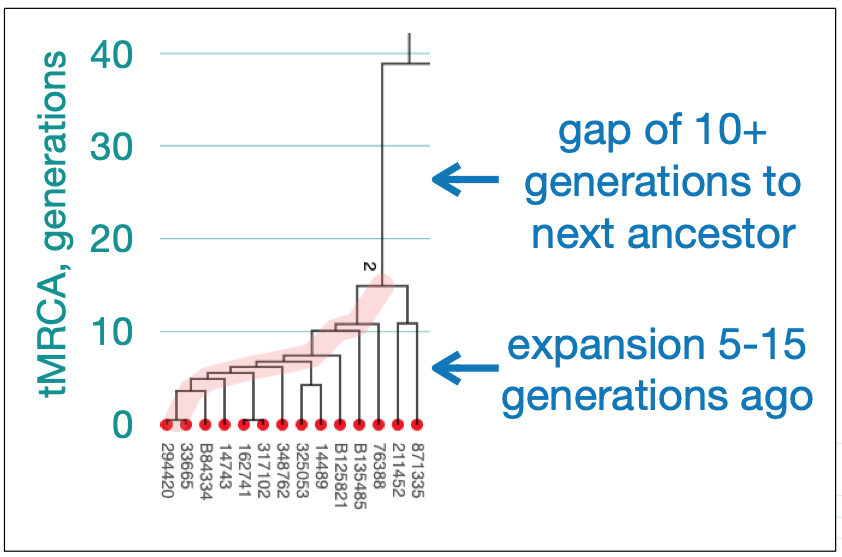
Y-STR analysis can also identify patterns which suggest the structure of American colonial families. Typically there will be a gap of 10 or more genetic generations followed by an expansion of family ties. [29].
Illustration 12: Spot the American Immigrant Families
The information in Table Three displays Y-Chromosome DNA (Y-DNA) STR results for testers in the L-497 Haplogroup project. Specifically, it provides STR data on my haplotype (STR signature), which is highlighted in the table, for 111 sampled STR values. My results are grouped with eleven other men based on our similarity in our respective STR haplotype signatures. We also share similarities in SNP tests and have been grouped in the G-BY211678 haplogroup.
Table Three: 111 STR Results for G-L497 Working Group Members within the G-BY211678 Haplotree Branch

The table provides the modal haplotype for the twelve individuals (re: third row) and the minimum and maximum values for each of the STRs listed in the table. FTDNA uses the concept of genetic distance (GD) to compare and evaluate genetic resemblance of two or more STR haplotypes.
It is at this point we start to compare STRs test results among potential test kits to determine if I find any genetic relatives!
What’s Next
Working with Y-STRs and Y-SNPs requires covering the topics of genetic distance, modal, ancestral haplotypes and the Most Recent Common Ancestor. In the context of these concepts, I will demonstrate the use of some of the Y-SNP & Y-STR Tools listed in Table One.
Sources
Feature Image of the story is a modified version of a featured image from Human Genomic Variation, National Human Genome Research Institute, National Institute of Health (NIH), Page last updated: April 6, 2018, https://www.genome.gov/dna-day/15-ways/human-genomic-variation . It is a visual depiction of comparing SNP mutations between two DNA testers. Aside from the image itself, the article is a good read.
[1] “People usually submit DNA samples in hopes of finding relatives they didn’t know about; just one or two matches might help to complete a family tree or resolve an old debate. However, some men doing Y DNA tests find themselves with an unexpected problem: they’re deluged with dozens to hundreds of “matches” who don’t share a common surname. With further effort they find that these matches are completely unrelated. It appears that somehow all of these men, though unrelated, have converged on a common DNA pattern”
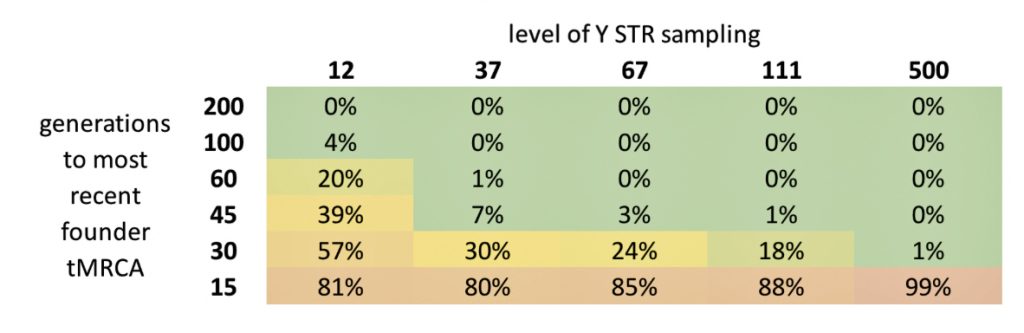
The table below summarizes risk level of convergence. The values are the percent of modern descendants that you would see as matches, using FTDNA’s criterion for the Most Recent Common Ancestor (tMRCA) of less than 21 generations, despite having no family structure other than one founder event.
It is notable that even as recent as 15 generations ago, a high percentage of testers will likely be identified as related because all descendants who share a founder event more recent than 21 generations will be marked as matches. This is frequently seen for emigration-driven founder events such as European emigration to North America and all occurred more recently. While these matches really reflect recent shared ancestry, it makes it difficult to reveal family details.
Rob Spencer, Convergence, Tracking Back: a website for genetic genealogy tools, experimentation, and discussion, no date, page accessed 3 May 2022.
Maurice Gleeson, Convergence – what is it?, 25 May 2017, DNA and Family Tree Research, https://dnaandfamilytreeresearch.blogspot.com/2017/05/convergence-what-is-it.html
Maurice Gleeson, Convergence – quantifying Back & Parallel Mutations (Part 1), 1 June 2017, DNA and Family Tree Research, https://dnaandfamilytreeresearch.blogspot.com/2017/06/convergence-quantifying-back-parallel.html
J David Vance, The Genealogist Guide to Genetic Testing, 2020, Chapter 6
See, Convergence, International Society of Genetic Genealogy Wiki, Page last updated 6 Dec 2018
Rob Spencer has a cogent explanation of convergence: See quote below and reference: Robert W. Spencer , Tracking Back: a website for genetic genealogy tools, experimentation, and discussion, no date, page accessed 3 May 2022.
“The men in question actually are related — this is key — but in a particular way and usually long before the genealogical time span of a couple of hundred years. A group of modern descendants might not care if they have a common ancestor who lived in 1000 AD — but it really matters.”
[2] Y-STR Results Guide, FamilyTree DNA Help Center, https://help.familytreedna.com/hc/en-us/articles/4408063356303-Y-STR-Results-Guide-#panel-4-48-60–0-4
Caleb Davis, Michael Sager, Göran Runfeldt, Elliott Greenspan, Arjan Bormans, Bennett Greenspan, and Connie Bormans, Big Y 700 White paper, March 27, 2019, https://blog.familytreedna.com/wp-content/uploads/2018/06/big_y_700_white_paper_compressed.pdf
Marty Brady, Y Chromosomes and the SNPs STRs, May 16 2020 Presentation, Albuquerque Genealogical Society, Ychromosome_slides.pdf
Ian McDonald, Exploring new Y-DNA Horizons with Big Y-700 19 Oct 2019, presentation was originally given as part of Genetic Genealogy Ireland 2019. https://familytreewebinars.com/webinar/exploring-new-y-dna-horizons-with-big-y-700/]
[3] Y-DNA tools, International Society of Genetic Genealology Wiki, This page was last edited on 30 June 2022, https://isogg.org/wiki/Y-DNA_tools
Rob Spencer, Deep STR Time, Tracking Back: a website for genetic genealogy tools, experimentation, and discussion, http://scaledinnovation.com/gg/gg.html?rr=deeptime
[4] Rob Spencer, Case Studies in Macro Genealogy, Presentation for the New York Genealogical and Biographical Society, July 2021, Slide 12, http://scaledinnovation.com/gg/ext/NYG&B_webinar.pdf
[5] Rob Spencer, STR Clades, Tracking Back: a website for genetic genealogy tools, experimentation, and discussion, http://scaledinnovation.com/gg/gg.html?rr=strclades
[6] Rob Spencer, Why use STR data and not SNP data?, Tracking Back: a website for genetic genealogy tools, experimentation, and discussion, http://scaledinnovation.com/gg/gg.html?rr=whystr
[7] Introduction to Group Projects, Family Tree DNA Center, https://help.familytreedna.com/hc/en-us/articles/4503173806351-Introduction-to-Group-Projects-
Group Projects, Family Tree DNA Learning Center, https://learn.familytreedna.com/topics/group-projects/
Should I Join A Group Project, Family Tree DNA Blog, Aug 10 2018, https://blog.familytreedna.com/should-i-join-a-group-project/
FamilyTreeDNA Group Projects, Family Tree DNA, https://www.familytreedna.com/group-project-search?browse=true
[8] This example is taken from J David Vance, The Genealogist Guide to Genetic Testing, 2020
[9] SNPs are given names based on an abbreviation that indicates the lab or research team that discovered the SNP and a number that indicates the order in which it was discovered. The prefix, the first letter or group of letters after the main alpha Haplogroup letter identifies the lab or analysis company which first discovered the SNP or was really the first to decide that the mutation at that position on the Y- chromosome was worthy of a name.
SNPs development indicated by beginning letters:
A = Thomas Krahn, MSc (Dipl.-Ing.), YSEQ.net, Berlin, Germany
ACT = Ancient-Tales Institute of Anthropology, Enlighten BioTech Co., Ltd., Shanghai, China
AD = Dr. Mohammed Al Sharija, Ministry of Education (Kuwait)
AF = Fernando Mendez, Ph.D., University of Arizona, Tucson, Arizona
ALK = Ahmad Al Khuraiji
AM or AMM = Laboratory of Forensic Genetics and Molecular Archaeology, UZ Leuven, Leuven, Belgium
B = Estonian Genome Centre
BY = Big Y testing (next generation sequencing) discovered with the BigY-500, Family Tree DNA, Houston, Texas
BZ = Q-M242 Project, Family Tree DNA, Houston, TX. SNPs named in honor of Barry Zwick.
CTS = Chris Tyler-Smith, Ph.D., The Wellcome Trust Sanger Institute, Hinxton, England
DC = Dál Cais, an Irish group believed to be descended from Cas, b. CE 347, related to SNP R-L226; Dennis Wright
DF = anonymous researcher using publicly available full-genome-sequence data, including 1000 Genomes Project data; named in honor of the DNA-Forums.org genetic genealogy community
E = Bulat Muratov
F = Li Jin, Ph.D., Fudan University, Shanghai, China
F* = Chuan-Chao Wang, Hui Li, Fudan University, Shanghai, China (Beginning letter F; second letter Haplogroup, i.e. FI is Fudan Haplogroup I)
FGC = Full Genomes Corp. of Virginia and Maryland
FT = Big Y testing (next generation sequencing)discovered with the Big Y-700, Family Tree DNA, Houston, Texas
G = Verónica Gomes, IPATIMUP Instituto de Patologia e Imunologia Molecular da Universidade do Porto (Institute of Molecular Pathology and Immunology of the University of Porto)
GG=Vavilov Institute of General Genetics, Russian Academy of Sciences, Moscow, Russia
IMS-JST = Institute of Medical Science-Japan Science and Technology Agency
JD = David Stedman using Big Y and other NGS sources.
JFS = John Sloan
JN = Jakob Nortsedt-Moberg
K = Youngmin JeongAhn, Ph.D; Education: Seoul National University and the University of Arizona
KHS = Functional Genomics Research Center, Korea Research Institute of Bioscience and Biotechnology
KL = Key Laboratory of Contemporary Anthropology, School of Life Sciences and Institutes of Biomedical Sciences, Fudan University, Shanghai, China
KMS = Segdul Kodzhakov; Albert Katchiev; Anatole Klyosov; Astrid Krahn; Thomas Krahn; Bulat Muratov; Chris Morley; Ramil Suyunov; Vadim Sozinov; Pavel Shvarev; SF “National clans DNA project”; EHP “Suyun” Ph.D. of Technical Science; Prof. Elsa Khusnutdinova, Sc.D. of Biological Sciences, Laboratory of Molecular Human Genetics, Institute of Biochemistry and Genetics, Ufa Research Centre, Russian Academy of Sciences
L = Thomas Krahn, MSc (Dipl.-Ing.) formerly of Family Tree DNA’s Genomics Research Center; snps named in honor of the late Leo Little
M = Peter Underhill, Ph.D. of Stanford University
MC = Christopher McCown, University of Florida; Thomas Krahn, MSc (Dipl.-Ing.), YSEQ.net, Berlin, Germany
MF = 23mofang BioTech Co., Ltd., Chengdu, China
MPB = Thomaz Pinotti and Fabrício R. Santos, Laboratório de Biodiversidade e Evolução Molecular (LBEM), Universidade Federal de Minas Gerais, Brazil
MZ = Hamma Bachir, Ph.D., E-M183 Project
N = The Laboratory of Bioinformatics, Institute of Biophysics, Chinese Academy of Sciences, Beijing
NWT = Northwest Territory, Theodore G. Schurr, Ph.D., Laboratory of Molecular Anthropology, University of Pennsylvania, Philadelphia, PA
P = Michael Hammer, Ph.D. of University of Arizona
Page, PAGES or PS = David C. Page, Whitehead Institute for Biomedical Research
PF = Paolo Francalacci, Ph.D., Università di Sassari, Sassari, Italy
PH = Pille Hallast, Ph.D., University of Leicester, Department of Genetics, United Kingdom
PK = Biomedical and Genetic Engineering Laboratories, Islamabad, Pakistan
PLE = Stanislaw Plewako, M. Sci, Baltic Sea DNA Project.
PR = Primate (gorilla and chimpanzee), Thomas Krahn’s WTTY. Some sources have not provided new names when same mutation found independently in humans.
RC = Major Rory Cain, BA(hons), BEd, BSc.
S = James F. Wilson, D.Phil. at Edinburgh University
SA = South America, Theodore G. Schurr, Ph.D., Laboratory of Molecular Anthropology, University of Pennsylvania, Philadelphia, PA
SK = Mark Stoneking, Ph.D., Max Planck Institute for Evolutionary Anthropology, Leipzig, Germany
SUR = Southern Ural; SF “National clans DNA project”; B.A. Muratov; EHP “Suyun” Ph.D. of Technical Sciences; Ramil Suyunov; Prof. E.K. Khusnutdinova, Sc.D. of Biological Sciences, Laboratory of Molecular Human Genetics, Institute of Biochemistry and Genetics, Ufa Research Centre Russian Academy of Sciences; Alexander Zolotarev; Igor Rozhanskii; Bayazit Yunusbaev, Institute of Biochemistry and Genetics, Ufa Research Centre, Russian Academy of Sciences
TSC = Gudmundur A. Thorisson and Lincoln D. Stein, The SNP Consortium, Cold Spring Harbor Laboratory, Cold Spring Harbor, NY
U = Lynn M. Sims, University of Central Florida; Dennis Garvey, Ph.D. Gonzaga University; and Jack Ballantyne, Ph.D., University of Central Florida
V = Rosaria Scozzari and Fulvio Cruciani, Dipartimento di Biologia e Biotecnologie “Charles Darwin” , Sapienza Università di Roma, Rome, Italy.
VK = Viacheslav Kudryashov.
VL = Vladimir Volkov, Tomsk University, Russia
Y = Y Full Team (Russian) using data from published and commercial next-generation sequencing samples
YP = SNPs identified by citizen scientists from genetic tests, then submitted to the Y Full team for verification.
YSC = Thomas Krahn, MSc (Dipl.-Ing.) formerly of Family Tree DNA’s Genomics Research Center
Z = Gregory Magoon, Ph.D., Richard Rocca, Vince Tilroe, David F. Reynolds, Bonnie Schrack, Peter M. Op den Velde Boots, Ray H. Banks, Roman Sychev, Victar Mas, Steve Fix, Christian Rottensteiner, Alexander R. Williamson, Ph.D., John Sloan and an anonymous individual, independent researchers of publicly available whole genome sequence datasets, and Thomas Krahn, MSc (Dipl.-Ing.), with support from the genetic genealogy community.
ZP = Peter M. Op den Velde Boots, David Stedman using Big Y and other NGS sources.
ZQ = Gabit Baimbetov, Nurbol Baimukhanov “ShejireDNA project” and other members of the project.
ZS = Gregory Magoon, Ph.D., Aaron Salles Torres from samples from Full Genomes and the Big Y.
ZW = Michael W. Walsh using Big Y.
ZZ = Alex Williamson. Mutations in palindromic regions. Each ZZ prefix represents two possible SNP locations.
Source: Y-DNA Haplogroup Tree 2019-2020, version 15.73, 11 July 2020, Internal Society of Genetic Genealogy, https://isogg.org/tree/
A SNP discovered or identified by YFull starts with a “Y”; a SNP starting with a “BY” or “FT” was named by Family Tree DNA, a “FGC” SNP was named by Full Genomes Corporation, and an “A” SNP was named by YSEQ. An ‘M’ stands for the Human Population Genetics Laboratory at Stanford University.
For specific information on history of the haplotree and related nomenclature, see: International Society of Genetic Genealogy, Y-DNA Haplogrouptree 2019 – 2020, Version: 15.73 Date: 11 July 2020, https://isogg.org/tree/
See also: Y-DNA: FamilySearch, How SNPs Are Added to the Y Haplotree, YouTube Video, Feb 2022, https://www.youtube.com/watch?v=CGQaYcroRwY
[10] Maciamo Hay, Haplogroup G2a, (Y-DNA), Eupedia, Jan 2021, https://www.eupedia.com/europe/Haplogroup_G2a_Y-DNA.shtml
Rootsi, S., Myres, N., Lin, A. et al. Distinguishing the co-ancestries of haplogroup G Y-chromosomes in the populations of Europe and the Caucasus. Eur J Hum Genet 20, 1275–1282 (2012). https://doi.org/10.1038/ejhg.2012.86
[11] Some of the reasons for the differences between the various haplogroup trees are:
- Different databases: The databases of the tested men differ between companies and groups. The different databases reflect the SNPs and order of those SNPs that have been found through their analysis of that database. The different companies and analysis groups use different sources for there SNPs: their own testers (YFull does not test), academic databases, historical sources archeological site analysis.
- Synomyn SNPs: Different companies may select different synonyms for the same SNP even though the mutation may appear in same place on each of their Y-DNA haplotrees it may not have the same name. Oftentimes different labs or analysis companies will discover the same SNP and provide independent names for the SNP. Different companies may select different SNPs from the same equivalent block of SNPs that are part of a branch to represent a particular branch of the Y-DNA haplotree.
- Equivalent SNPS: Each of these haplogroup trees are developed by analyzing a group of tested men and developing a SNP mutation history that shows how these ancestors branched from each other. Many branches have died out before present day men were tested. As more men are tested, mutations will be found that are new but related to specific older branches. If a number of men who are tested by a given company and found to have new mutations they may form a new branch. However, the results from this one company may be viewed by other companies who manage other haplotrees as ‘private’ SNPs and therefore will not be viewed as a new branch.
- Selection Criteria: The companies also have different criteria for testing quality, region of the chromosome, for which SNPs belong on their haplogroup tree. SNPs which may be selected by one company may not be acceptable to another.
The three major organizations that manage Y-DNA haplogroups and haplotrees are:
[12] In 2002 the Y Chromosome Consortium (YCC) proposed two widely accepted nomenclature systems for Y-DNA haplogroups: an hierarchical system and a short hand system. Other systems have subsequently been developed and used.
Major haplogroups are labeled with large capital letters (A–T).
- Hierarchical system: The hierarchical system is based on characteristics of set theory. The capital letters (A–R) are used to identify the major clades and constitute the front symbols of all subsequent subclades. Subclades nested within each major haplogroup are defined by alternating numbers “1” and “2” and lowercase letters “a” and “b”. An example would be: G2a2b2a1a1b1a1b1a2b.
- Shorthand – SNP system: This system is more robust to changes in topology but widespread SNPs have often up to three synonymous names. Additionally different corporations/labs in many cases select an equivalent SNP for the same haplogroup as primary/defining (example G-M201). For seldom and new terminal SNPs there is also the risk that they are not unique (recurrent, unstable) or not detectable with all lab methods.
- Basic Hierarchy + Shorthand system: since 2013 this system is used by some publications to show the basic hierarchy under a main haplogroup combined with a SNP of a subclade deeper down then the listed hierarchy: example G2a (P15, U5, L31/S149). Especially for unknown SNP names this allows easier recogniation of the basal position.
- Paragroups are distinguished from haplogroups by using the * (star) symbol, which represents chromosomes belonging to a clade but not its researched subclades defined in the same publication.
Y-DNA project help, International Society of Genetical Genealogy Wiki, This page was last edited on 28 October 2022, https://isogg.org/wiki/Y-DNA_project_help
See also: Y Chromosome Consortium. A nomenclature system for the tree of human Y-chromosomal binary haplogroups. Genome Res. 2002 Feb;12(2):339-48. doi: 10.1101/gr.217602. PMID: 11827954; PMCID: PMC155271. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC155271/
Karafet TM, Mendez FL, Meilerman MB, Underhill PA, Zegura SL, Hammer MF (2008-05). “New binary polymorphisms reshape and increase resolution of the human Y chromosomal haplogroup tree”. Genome Research. doi:10.1101/gr.7172008. Retrieved 2012-04-12
[13] Let’s All Start Using Terminal SNP Labels Instead of Y Haplogroup Subclade Names, Okay? http://www.yourgeneticgenealogist.com/2012/09/lets-all-start-using-terminal-snp.html
Family Tree DNA, Y-DNA: How SNPs Are Added to the Y Haplotree, YouTube Video, Feb 2022, https://www.familysearch.
[14] The FamilyTreeDNA (FTDNA) Time to Most Recent Common Ancestor (TMRCA) estimate (Beta) is calculated based on SNP and STR test results from present-day DNA testers. The uncertainty in the molecular clock and other factors is represented in this probability plot, which shows the statistical probability of the reliability of the birth date in statistical stand deviations, e.g. the most likely time when the common ancestor was born among statistical possibilities.
[15] Rootsi, S., Myres, N., Lin, A. et al. Distinguishing the co-ancestries of haplogroup G Y-chromosomes in the populations of Europe and the Caucasus. Eur J Hum Genet 20, 1275–1282 (2012). https://doi.org/10.1038/ejhg.2012.86
[16a] Big Y Block Tree Introduction, FTDNA Help Center, https://help.familytreedna.com/hc/en-us/articles/4402744197647-Big-Y-Block-Tree-Introduction#accessing-the-block-tree-0-0
[16] See Line 1135 column S and T in 2019-2020 Haplogroup G TreeY-DNA Haplogroup Tree 2019-2020, International Society of Genetic Genealoloy (ISSOG), Version: 15.73 Date: 11 July 2020 https://docs.google.com/spreadsheets/d/111Iqo0vRt-sr8MJT7pavKQ0qoWxYSc1P7hnMRq3GijU/edit#gid=0
For YFULL SNP designations in their haplotree:
Q: How does YFull determine my Terminal Hg?
A: YFull seeks to place your sample in the YTree as near to the present as is possible by comparing your path of SNP mutations with the paths of SNP mutations of other samples in its database. A “path of mutations” is a list of mutations ranked by the estimated age of each mutation.
If your mutations exactly match those of another sample in the database, your sample will be placed in the same subclade as the other sample and this will be the Terminal Hg (or subclade) of both samples.
In some cases a sample may include an * (asterisk) to indicate that YFull was not able to match the sample with another sample beyond the specified location in the YTree.
At the time you pay your fee to YFull, the location of your sample in the YTree is temporary. When the next version of the YTree is released your Terminal Hg may change. Also, as more samples are added to the YFull database, your Terminal Hg may continue to change.
YFULL FAQ, Last updated on March 28, 2018. https://www.yfull.com/faq/how-my-sample-located-on-ytree/ also https://www.yfull.com/faq/
[17] Y-DNA project help, International Society of Genetic Genealogy Wiki, This page was last edited on 28 October 2022, https://isogg.org/wiki/Y-DNA_project_help
J David Vance, The Genealogist Guide to Genetic Testing, 2020, Chapter 7
[17a] Rob Spencer, Additional Information for the RootsTech 2022 session “Extending Time Horizons with DNA”, Tracking Back, http://scaledinnovation.com/gg/ext/rt22/info.html?rt
[17b] Rober Spencer, Additional Information for the RootsTech 2022 session “Extending Time Horizons with DNA”, Extinction of Lineages and Surnames, http://scaledinnovation.com/gg/ext/rt22/info.html?rt
[18] The following reflect all of the SNPS associated with the FTDNA G Haplogroup SNPS that I have either tested positive or are presumed positive for the following equivalent variants for each Y-DNA branch. Each SNP mutation represents an individual that is a direct ancestor.
G-M201 root branch: 318 variants
M201, BY21262, BY21263, BY21264, BY2378, CTS10026, CTS1010, CTS1013, CTS10280, CTS1029, CTS10393, CTS10706, CTS10721, CTS10723, CTS10824, CTS10945, CTS11185, CTS11228, CTS11331, CTS1137, CTS1139, CTS11400, CTS11529, CTS11584, CTS11670, CTS11702, CTS11907, CTS11911, CTS12040, CTS12240, CTS12309, CTS1259, CTS12600, CTS12654, CTS1270, CTS12704, CTS12731, CTS1283, CTS12949, CTS13035, CTS1437, CTS1574, CTS1577, CTS1612, CTS1613, CTS1624, CTS1705, CTS1726, CTS175, CTS1750, CTS1768, CTS189, CTS1997, CTS2016, CTS2120, CTS2125, CTS2126, CTS2136, CTS2174, CTS2215, CTS2251, CTS2271, CTS2357, CTS2506, CTS2517, CTS2624, CTS282, CTS34, CTS3693, CTS373, CTS3752, CTS4101, CTS4238, C50S440, CTS4479, CTS4523, CTS4613, CTS4749, CTS4761, CTS4887, CTS5317, CTS5414, CTS5498, CTS5504, CTS5640, CTS5658, CTS5699, CTS5757, CTS5837, CTS6073,CTS635, CTS6483, CTS670, CTS6807, CTS6894, CTS692, CTS6936, CTS6957, CTS7092, CTS7269, CTS7388, CTS7674, CTS7929, CTS8023, CTS827, CTS8531, CTS8717, CTS9011, CTS9190, CTS9593, CTS9641, CTS9707, CTS9710, CTS9894, CTS995, FGC77405, FGC77406, FGC77410, FGC77412, FGC77414, FGC77417, FGC77418, FGC78561, FGC79229, FGC79248, FT32, FT32899, L109, L116, L1258, L1342, L1407, L154, L204, L269, L382, L402, L519, L520, L521, L522, L523, L524, L605, L769, L770, L836, L837, M3438, M3453, M3468, M3489, M3569, M3598, M3601, P257, PF2788, PF2790, PF2791, PF2793, PF2796, PF2802, PF2804, PF2805, PF2806, PF2808, PF2809, PF2815, PF2816, PF2817, PF2819, PF2821, PF2827, PF2831, PF2832, PF2836, PF2837, PF2844, PF2857, PF2858, PF2859, PF2861, PF2862, PF2865, PF2866, PF2867, PF2868, PF2869, PF2871, PF2872, PF2873, PF2874, PF2875, PF2876, PF2877, PF2878, PF2879, PF2880, PF2881, PF2884, PF2888,PF2889, PF2890, PF2894, PF2896, PF2901, PF2902, PF2908, PF2910, PF2914, PF2915, PF2917, PF2918, PF2919, PF2920, PF2921, PF2932, PF2949, PF2954, PF2956, PF2958, PF3022, PF3045, PF3046, PF3048, PF3049, PF3050,PF3052, PF3053, PF3054, PF3057, PF3059, PF3061, PF3063, PF3065, PF3067, PF3068, PF3069, PF3070, PF3071, PF3074, PF3075, PF3076, PF3077, PF3080, PF3083, PF3085, PF3087, PF3088, PF3092, PF3094, PF3103, PF3117, PF3118, PF3121, PF3122, PF3123, PF3134, PF3265, S13661, S13716, S14351, S8863, U17, U2, U20, U21, U3, U33, U7, Y226, Y229, Y231, Y235, Y239, Y245, Y246, Y258, Y271, Y303, Y309, Y332, Y345, Y351, Y375, Y383, Y390, Z3030, Z3067, Z3069, Z3078, Z3080, Z3081, Z3097, Z3104, Z3107, Z3117, Z3135, Z3136, Z3144, Z3145, Z3239, Z3246, Z3247, Z3248, Z3250, Z3262, Z3477, Z3482, Z3485, Z3539, Z6041, Z6116, Z6133, Z6138, Z6324, Z6472
Variants haplogroup G-L89 branch: 32 variants
L89, CTS10089, CTS11196, CTS120, CTS1868, CTS2593, CTS4413, F3198, FGC7254, FGC79817, L142.1, L79.1, M3579, M3614, P287, PF2792, PF2794, PF2795, PF2807, PF2810, PF2830, PF2835, PF2860, PF2864, PF2887, PF2891, PF2895, PF2909, PF3093, PF3119, Z3060, Z3063
Variants haplogroup G-L156 branch: 62 variants
L156, CTS11016, CTS1900, CTS2406, CTS4136, CTS4242, CTS4264, CTS4703, CTS6316, CTS6692, CTS6742, CTS7430, CTS7662, CTS9885, F1239, F1496, F3070, F3220, F3226, FGC37627, FGC77409, L496, PF2785, PF2787, PF2789, PF2797, PF2800, PF2803, PF2814, PF2820, PF2839, PF2840, PF2893, PF2897, PF2898, PF2904, PF2905, PF2912, PF3007, PF3047, PF3091, PF3095, PF3120, PF3125, S13969, V1943, Y125206, Y1415, Y222, Y237, Y238, Y255, Y289, Y321, Y360, Y380, Z3042, Z3056, Z3112, Z3499, Z6105, Z6292
Variants haplogroup G-P15 branch: 57 variants
P15, CTS11463, CTS11627, CTS1879, CTS211, CTS32, CTS5416, CTS5666, CTS6026, CTS6314, CTS6630, CTS6753, CTS8673, CTS9318, F1554, F1975, F1980, F2274, F2301, F2529, F3734, F4086, FGC77420, FGC77421, FGC78558, FGC79059, L149, L31, M3348, M3392, PF2798, PF2799, PF2833, PF2903, PF2911, PF2972, PF2993, PF3034, PF3043, PF3051, PF3056, PF3060, PF3066, PF3073, PF3078, PF3079, PF3082, PF3084, PF3086, U5, Y244, Y251, Y298, Y384, Z3114, Z3506, Z6125
Variants haplogroup G-L1259 branch: 7 variants
L1259, CTS2951, FGC77407, FGC77411, FT81076, PF2824, PF2826
Variants haplogroup G-L30 branch: 47 variants
L30, CTS10449, CTS1093, CTS11324, CTS11434, CTS1180, CTS12810, CTS376, CTS4227, CTS5463, CTS574, CTS7992, CTS90, CTS9763, F1136, F1733, F3139, F788, FGC81433, FGC81737, L1257, L1260, L190, L32, PF2811, PF2838, PF2870, PF2913, PF3028, PF3089, PF3090, PF3254, PF3270, PF3276, PF3277, PF3278, PF3280, PF3281, Y359, Z3047, Z3051, Z3086, Z3103, Z3238, Z3260, Z3465, Z3487
Variants haplogroup G-L141 branch: 14 Variants
L141, CTS1891, CTS2488, CTS8143, CTS9605, CTS9957, F2121, FGC81432, PF2813, PF2818, PF3275, Y378, Z3058, Z3074
Variants haplogroup G-P303 branch: 38 variants
P303, CTS10366, CTS10725, CTS1949, CTS424, CTS4454, CTS6719, CTS688, CTS7698, CTS946, FGC81739, FGC82651, PAGES00098, PF3329, PF3330, PF3332, PF3333, PF3339, PF3342, PF3343, S8782, Y125207, Y253, Y270, Y350, Y354, Y382, Z3481, Z3488, Z3489, Z3490, Z3491, Z3492, Z3493, Z3494, Z3495, Z3496, Z6136
Variants haplogroup G-L140: branch 14 variants
L140, CTS12570, CTS12891, CTS796, PF2823, PF3331, PF3337, Y307, Y324, Z3155, Z3220, Z3245, Z3501, Z767
Variants haplogroup G-PF3346 branch: 1 variant
PF3346
Variants haplogroup G-PF3345 branch: 3 variants
PF3345, FGC799, Z3065
Variants haplogroup G-CTS342 branch: 5 variants
CTS342, CTS2821, Z3039, Z3049, Z723
Variants haplogroup G-L497 branch: 49 variants
L497, BY34319, CTS12867, CTS12895, CTS1899, CTS4197, CTS5351, CTS5762, CTS6235, CTS7111, CTS8596, F3464, FGC470, FGC472, FGC81738, FGC81741, FGC8301, FGC85467, PF6850, PF6852, S10780, Z1822, Z3041, Z3108, Z3147, Z3149, Z3160, Z3169, Z3173, Z3181, Z3207, Z3212, Z3283, Z3390, Z3480, Z3513, Z3528, Z6379, Z730, Z731, Z732, Z733, Z734, Z736, Z737, Z744, Z749, Z750, Z756
Variants haplogroup G-CTS9737 branch: 12 variants
CTS9737, CTS11194, CTS5089, CTS6711, CTS7012, CTS730, Z1900, Z3035, Z3205, Z6380, Z729, Z735
Variants haplogroup G-Z1817 branch: 15 variants
Z1817, CTS11352, CTS11605, CTS3226, CTS8701, FGC475, S25662, Z1821, Z3141, Z3442, Z6900, Z6901, Z742, Z747, Z755
Variants haplogroup G-Z727 branch: 8 variants
Z727, CTS2100, CTS7142, Y3102, Z16776, Z3195, Z725, Z753
Variants haplogroup G-FGC477 branch: 2 variants
FGC477, FGC7516
Variants haplogroup G-Z6748 branch: 29 variants
Z6748, BY8142, FGC476, FGC479, FGC481, FGC482, FGC483, FGC484, FGC485, FGC487, FGC488, FGC490, FGC496, FGC498, FGC499, FGC500, FGC502, FGC504, FGC505, FGC506, FGC507, FGC509, FGC511, FGC512, FGC516, FGC517, FGC518, FT73641, Y172988
Variants haplogroup G-Y38335 branch: 2 variants
Y38335, Y132516
Variants haplogroup G-FGC486 branch: 5 variants
FGC486, FGC492, FGC494, FGC497, FGC7517
Variants haplogroup G-Z40857 branch: 5 variants
Z40857, FGC510, Y132533, Z40860, Z5838
Variants haplogroup G-Y132505 branch: 2 variants
Y132505, FT47083
Variants haplogroup G-BY211678 brach: 4 variants
BY211678, BY151390, FT47770, Y13253
[19] Andrew Curry, The first Europeans weren’t who you might think, National Geographic, August 2019, https://www.nationalgeographic.com/culture/article/first-europeans-immigrants-genetic-testing-feature
See also:
David Reich, Who We are and How We got Here, Ancient DNA and the New Science of the Human Past, New York: Vintage Books, 2018
Early European Farmers, Wikipedia, This page was last edited on 5 February 2023, https://en.wikipedia.org/wiki/Early_European_Farmers
Reich, David Who We are and how We Got Here: Ancient DNA and the New Science of the Human Past. Oxford University Press. 2018
Lazaridis, Iosif; et al. (July 25, 2016). “Genomic insights into the origin of farming in the ancient Near East”. Nature. Nature Research. 536(7617): 419–424. Bibcode:2016Natur.536..419L. doi:10.1038/nature19310. PMC 5003663. PMID 27459054 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5003663/
González-Fortes, Gloria; et al. (June 19, 2017). “Paleogenomic Evidence for Multi-generational Mixing between Neolithic Farmers and Mesolithic Hunter-Gatherers in the Lower Danube Basin”. Current Biology. Cell Press. 27 (12): 1801–1810. doi:10.1016/j.cub.2017.05.023. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5483232/
Lazaridis, Losif (December 2018). “The evolutionary history of human populations in Europe”. Current Opinion in Genetics & Development. Elsevier. 53: 21–27. arXiv:1805.01579. doi:10.1016/j.gde.2018.06.007https://www.sciencedirect.com/science/article/abs/pii/S0959437X18300583
Shennan, Stephen (2018). The First Farmers of Europe: An Evolutionary Perspective. Cambridge World Archaeology. Cambridge University Press. doi:10.1017/9781108386029. ISBN 9781108422925
Nikitin, Alexey G.; et al. (December 20, 2019). “Interactions between earliest Linearbandkeramik farmers and central European hunter gatherers at the dawn of European Neolithization”. Scientific Reports. Nature Research. 9 (19544): 19544. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6925266/
[20] “Before Present (BP) years, also known as “time before present” or “years before present“, is a time scale used mainly in archaeology, geology and other scientific disciplines to specify when events occurred relative to the origin of practical radiocarbon dating in the 1950s. Because the “present” time changes, standard practice is to use 1 January 1950 as the commencement date (epoch) of the age scale.”
Before Present, Wikipedia, This page was last edited on 29 January 2023, https://en.wikipedia.org/wiki/Before_Present
Regarding the bottleneck, see the following articles:
Karmin, M. et al. A recent bottleneck of Y chromosome diversity coincides with a global change in culture. Genome Res. 25, 459–466 (2015), https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4381518/
Premo, L. S. Hitchhiker’s guide to genetic diversity in socially structured populations. Curr. Zool. 58, 287–297 (2012).
Batini, C. et al. Large-scale recent expansion of European patrilineages shown by population resequencing. Nat. Commun. 6, 7152 (2015).
Poznik, G. D. et al. Punctuated bursts in human male demography inferred from 1,244 worldwide Y-chromosome sequences. Nat. Genet. 48, 593–599 (2016).
[21] Caril Zimmer, In Ancient DNA, Evidence of Plague Much Earlier Than Previously Known, NY Times, Oct 22, 2015, https://www.nytimes.com/2015/10/23/science/in-ancient-dna-evidence-of-plague-much-earlier-than-previously-known.html.
Rasmussen S, Allentoft ME, Nielsen K, Orlando L, et al, Early divergent strains of Yersinia pestis in Eurasia 5,000 years ago. Cell. 2015 Oct 22;163(3):571-82. doi: 10.1016/j.cell.2015.10.009. Epub 2015 Oct 22. PMID: 26496604; PMCID: PMC4644222. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4644222/
Pooja Swali1, Rick Schulting, Alexandre Gilardet, et al, Yersinia pestis genomes reveal plague in Britain 4,000 years ago, January 26, 2022, bioRXiv, https://www.biorxiv.org/content/10.1101/2022.01.26.477195v1.full.pdf
[22] Batini, C., Hallast, P., Zadik, D. et al. Large-scale recent expansion of European patrilineages shown by population resequencing. Nature Communications 6, 7152 (2015). https://doi.org/10.1038/ncomms8152.
Zeng, T.C., Aw, A.J. & Feldman, M.W. Cultural hitchhiking and competition between patrilineal kin groups explain the post-Neolithic Y-chromosome bottleneck. Nature Communications 9, 2077 (2018). https://doi.org/10.1038/s41467-018-04375-6
[23] Zeng, T.C., Aw, A.J. & Feldman, M.W. Cultural hitchhiking and competition between patrilineal kin groups explain the post-Neolithic Y-chromosome bottleneck. Nature Communications 9, 2077 (2018). https://doi.org/10.1038/s41467-018-04375-6
James McNish, The Beaker people: a new population for ancient Britain, Natural History Museum, 22 Feb 2018, https://www.nhm.ac.uk/discover/news/2018/february/the-beaker-people-a-new-population-for-ancient-britain.html
Bell Beaker culture, Wikipedia, This page was last edited on 5 February 2023, https://en.wikipedia.org/wiki/Bell_Beaker_culture
[24] Rob Spencer, SNP Tracker, Tracking Back: A Website for Genetic Genealology Tools, experimentation, and discussion, http://scaledinnovation.com/gg/snpTracker.html
[25] Maps of Neolithic & Bronze Age Migrations Around Europe, Eupedia, https://www.eupedia.com/europe/neolithic_europe_map.shtml
[26] Y-DNA Tools, International Organization of Genetic Genealology Wiki, This page was last edited on 30 June 2022, https://isogg.org/wiki/Y-DNA_tools
[27] Rob Spencer, Introduction to Distance Dendrograms, Tracking Back: A Website for Genetic Genealology Tools, experimentation, and discussion, http://scaledinnovation.com/gg/gg.html?rr=ddintro
[28] Rob Spencer, The Big Picture of Y STR Patterns, The 14th International Conference on Genetic Genealogy, Houston, TX March 22-24, 2019, http://scaledinnovation.com/gg/ext/RWS-Houston-2019-WideAngleView.pdf Page 11
[29] Rob Spencer, The Big Picture of Y STR Patterns, The 14th International Conference on Genetic Genealogy, Houston, TX March 22-24, 2019, http://scaledinnovation.com/gg/ext/RWS-Houston-2019-WideAngleView.pdf Page 12